Dr. Cornelius G. Hunter, a Biophysicist and Computational Biologist at Biola, wrote an excellent paper on the evolutionary predictions made by theorists and the unexpected findings that followed. Unfortunately, Dr. Hunter’s website no longer has this article available for viewing.
Therefore, I have decided to temporarily make the document available here. That is, until either Dr. Hunter requests I take it down, he republishes, or submits a revised version. I assume the former will not happen, since the article was public and free to view.
If you haven’t read it before, I suggest you do so. It is well worth it.
Recently the popular creation skeptic Randal Rauser, who goes by the Youtube moniker of “The Tentative Apologist,” posted a video titled, “Why Young Earth Creationism is Irrational and Harmful.” In it, he laid out his case for why evangelicals should not embrace young earth creation as well as a general methodology for laymen wherein they conform to the expert opinion—specifically the expert majority opinion. While I do believe he is good-hearted and well meaning, the video exemplified the innate depravity of the modern “scientismist” view. He covered the bases so well and so thoroughly that I thought it apt to do an in-depth exegesis and logical analysis of the claims he made. My hope is that this case study can be instructive on how to critically think, this is not meant to be a dunk on Rauser.
Argument #1: Social Contingency
He begins his criticism of the young earth creationist movement by citing the book “The Creationists” by Ronald Numbers. Dr. Numbers is a historian of science who was the son of a fundamentalist Seventh-day Adventist preacher and later left becoming a self-proclaimed agnostic. Numbers’ thesis is that the modern movement of creationism began as an Adventist movement. Rauser notes:
“The modern creationist movement actually comes from Seventh Day Adventism and particularly young earth creationist George McCready Price… As a result, young earth creationism became the mainstream view held by the emerging fundamentalist movement of the 1920-30s which was a reaction to the growth and perceived compromise of mainstream denominations and university-based divinity schools.”
The real beginnings of modern creationism started not by an Adventist in the 20s but by Baptists in the 60s. Although Rauser acknowledges this, he points out that “The Genesis Flood” by Morris and Whitcomb was heavily influenced by Price’s work several decades earlier. While it is true that Price played a large role in the model put forth in the 60s, it is important to note that Price, Morris, and Whitcomb were not writing in a vacuum.
Who was Price influenced by? And if we are to say (rightly) not by Adventists, then you cannot simply argue that modern young earth creationism is an adventist movement.
Price was citing Anglicans, Presbyterians, Congregationalists, Baptists, and Reformed geologists. To name a few non-adventist geologists: Thomas Burnet (Telluris Theoria Sacra, 1681), John Woodward (An Essay Toward a Natural History of the Earth, 1695), William Whiston, Granville Penn, George Fairholme, Sharon Turner, George Young, George Bugg, John Murray, David Lord, and Tayler Lewis.
Seventh-Day Adventism wasn’t alone in holding to young earth creationism at that time, either. Many traditional Christian denominations—including Anglicans, Lutherans, and Eastern Orthodox all held semi-official doctrines or official dogmas on the young age of the earth. Figures like the Anglican Bishop James Ussher, Lutheran doctrines and dogmas such as the Westminster Standards (1643–1649) and the 1967 resolution of the LCMS affirmed the six day creation and young earth, and the Orthodox Anno Mundi calendar (held as the official calendar in most Eastern traditions) dates creation to approximately 5508 BC. Some modern Orthodox theologians argue that a literal reading of Genesis 1–2 remains the historic teaching of the church up until the 19th century.
While it is true, Price definitely filtered the former creationist flood models and understandings through his adventist interpretive framework, yet Morris and Whitcomb filtered Price through their Baptist/Evangelical framework.
This is all very important to bring up because Ronald Numbers’ view of the history of creationism is a very prevalent one in current culture and it is told by people who either fallaciously aim to discredit the movement as a prophetic fad or seek to over emphasize credit to Price, likewise to dismiss the important work of early creationist field geologists. Both of which count as genetic fallacies, of which we will cover shortly.
So, then, why does Rauser, himself, open with this remark (of all remarks)?
His answer:
“It doesn’t make young earth creationism right or wrong—it doesn’t tell you anything per se about the science, but it does show you the social contingent historical origins of the young earth creationist movement. And for people who are taught, then, that young earth creationism just is the standard historical orthodox christian perspective to understand and see through the lenses of a historian just how contingent and limited the origins of this modern movement are, really helps to contextualize it and raise the level of prima facie skepticism that one should have about this movement.”
Rauser is being fair when he points out this cannot be evidence of the truth of young earth creationism. And, for a second, I just want you to pause on that.
He has realized that if he were to do so, it would be a genetic fallacy. That is, it would be a dismissal of the arguments and evidence of creationism, not on the basis of evidence, but on the basis of source or origin.
Unfortunately for Rauser, the point he ends up making is likewise… a genetic fallacy. To argue that a movement, especially and particularly of the movement of scientific inquiry, can be discredited because the scientists who penned it were unorthodox is to deny the entire enterprise of science altogether.
He argues fallaciously to what end?
In order to “raise the level of prima facie skepticism.” Prima facie is latin for “at first sight.” What Rauser is communicating to us is that we should make a prior commitment to the falsity of the creationist movement.
Based on what grounds?
On the fallacious grounds of a socially contingent historical analysis, that is moreover historiographically asymmetric and based on the presuppositions of a former seventh day agnostic critical scholar. This is essentially a non-attempt to engage with any evidence (apart from pseudo history). In the philosophy of science, all movements are socially contingent.
To his credit he mentions Bishop James Ussher, however methinks he doth protest too much.
“And just to be cautious here, I do clarify that this is modern. There have been young earth creationists throughout history. The most famous example is Arch Bishop James Ussher, a British theologian and Bishop who attempted to date the origins of the universe to 4004 BC, writing in the seventeenth century. But his views aren’t the same as the modern young earth creationist movement that really traces to this influx of seventh day adventist prophetic theology into modern fundamentalism.”
Well, I’ve got exciting news, Rauser! Modern creationists don’t hold to Price’s view either. In fact, modern flood geology is based on models of catastrophic plate tectonics (CPT) which were exposited by Dr. John Baumgardner in the 90s. The model has been refined since then, but it is the model of neither Price nor Morris and Whitcomb.
This is what’s often called, in philosophy, a symmetry-breaker. You see, Rauser wanted so badly to articulate that early creationists, that are not Adventists, don’t count because they have different models. But if that rule were applied evenly, the start of the modern creationist movement would be pushed to the late 90s! If Rauser defines a movement by its specific mechanics (e.g., Price’s specific model), then he cannot logically link Morris and Whitcomb to Price while simultaneously distancing Ussher from Morris.
Argument #2: Appeal To Experts
Rauser begins his next line of argument with a question:
“The first thing I want to ask whenever people come up with a minority view is: ‘what do the experts say on a particular issue?’ This is true across the board. We should be very careful about engaging in special pleading where we apply a different standard in one area than another just because that suits our bias.”
The first thing I would like to ask Rauser is: what is an expert?
To evaluate who the experts are and which experts to defer to, you already need independent critical judgment. Yet, to say that we should rely on experts is an explicitly uncritical statement.
Rauser warns against special pleading, yet his own methodology treats historical science as if it were identical to operational science. We defer to “experts” like surgeons or pilots because their expertise is constantly validated by immediate, repeatable results. If a surgeon is “irrational,” the patient dies; if a pilot is “irrational,” the plane crashes.
In contrast, “experts” in historical geology or evolutionary biology are constructing narratives about the unobservable past. There is no immediate “feedback loop” from reality to verify their conclusions. By demanding the same level of uncritical deference for historical narrative as we give to operational technology, Rauser is the one engaging in a form of special pleading.
This is not to say Geologists don’t make predictions about, say, where to find oil, what rock strata will look like in unexplored regions, which fossils should exist in which layers… and those predictions get tested. But these are distinct from the narrative they tell about the data. The framework is what is in question in the origins debate, not the facts on the ground.
To make Rauser’s argument clear, we can formulate it in a syllogism:
Premise 1: Most minority views are wrong.
Premise 2: Creationism is a minority view.
Conclusion: Therefore, it is rational to assume Creationism is wrong.
While, you might suppose premise one to be statistically probable generally, the problem is that it’s an extremely weak inference that does almost no epistemic work, especially when the minority view comes with substantive arguments that need engaging on their merits.
It only takes a few history books to see that in every case, the maverick was right and the credentialed majority was wrong. Wegener had his continental drift theory rejected for decades by the geological establishment despite compelling evidence, Galileo was faced against ecclesiastical and academic authority simultaneously, Fleming was largely ignored for over a decade after discovering penicillin, and J Harlen Bretz proposed a massive catastrophic flood event which was ridiculed by the geological establishment for roughly 40 years. Other examples which we more readily accepted, but still independent thinkers are Copernicus, Bacon, Newton, Einstein, Pasteur, McClintock, Marshall and Warren with H. pylori.
That’s not to mention the founders of the mainstream paradigm: Hutton, Lyell, Darwin, Wallace, and Mendel. Hutton and Lyell had to fight tooth and nail against flood geology in intense philosophical debate. Darwin and Wallace spent decades contesting the theory of natural selection. Mendel was entirely ignored for 35 years and only rediscovered posthumously. Yet, these are their icons. This is literally historical amnesia. How can Rauser seriously be saying that we should just default to the consensus? How could any science be done that way?
This is not to say that creationism is right or that the minority is right. I only claim the epistemically humble position: the experts aren’t always right. However, can we embrace his less abrasive claims?
“Experts are not infallible, but all things being equal, you want to go with the experts… You don’t want to go, all things being equal, with the very significant minority.”
This is a particular and different claim. Notice that in the equation he’s drawn, there are no non-experts. But he argues, the majority of experts will be a better place to hang one’s hat—all things being equal.
All things being equal.
I want to highlight a couple angles on this qualifying phrase that Rauser uses. First, what does it mean for all else to be equal? How is that metric reached?
In order to evaluate equality, we need some metric to evaluate the models in question. This means evaluating their explanatory power, internal consistency, relation to the data, and presuppositions. Yet, by the time you’ve done this, you are no longer relying on the experts, you are doing the work of an expert.
Rauser is asking the layman to exercise a form of meta-expertise. He is suggesting that while a layman isn’t qualified to judge the geology, they are qualified to judge the geologists.
This is a precarious position. If a layman is not equipped to understand the nuances of Catastrophic Plate Tectonics (CPT) vs. Uniformitarianism, how are they equipped to judge the social and institutional pressures that produce a “majority”?
What’s more, in the origins debate, “all else” is never equal because the starting presuppositions are diametrically opposed. You can’t even get any kind of equality when the foundations of either edifice cannot be compared to begin with.
Argument #3: You Have To Teach!
He closes that section off with a criterion for engagement:
“Here’s a basic way to test your expertise: how prepared are you right now to give a one hour introductory lecture to any of these fields… geochemistry, or geochronology, or molecular biology?… The ability to give a one hour lecture is at least a minimal threshold to even have a further conversation.”
Rauser’s “one-hour lecture” rule is an elitist filter that ignores how human knowledge actually functions. You do not need a degree in geochemistry to identify a logical contradiction in a geochemist’s paper, nor do you need to be a molecular biologist to understand the statistical impossibility of certain evolutionary transitions.
Take the example of a court of law. In a court of law, we do not require jurors to be able to give a one-hour lecture on DNA sequencing or ballistics. We expect them to use their independent critical judgment to weigh the testimony of competing experts.
Furthermore, most experts are hyper-specialized. A molecular biologist might not be able to give a one-hour lecture on geochronology, yet Rauser would likely still accept their “expert” opinion on the age of the earth simply because they belong to the same “consensus club.”
Argument #4: You Have To Explain!
“If you are a young earth creationist and you’re dismissing 98-99% of experts, you then have to give an explanation for how 98-99% experts could be wrong about some significant issue like the age of the universe, the age of earth, and the origin of species upon the planet. And this is where we’re going to tend to come into accounts which are boarding in the dangerous area of conspiracy theories.”
Rauser says you “have to give an explanation” for how the experts could be wrong. The explanation is actually quite simple and historically grounded: Science is not a democracy. Truth is not determined by the number of PhDs who agree, but by the correspondence of a model to the physical data.
When the majority holds to a flawed paradigm, they will consistently interpret all new data to fit that paradigm (a process called “epicyclic adjustment”). It takes a maverick to step outside the circle and show that the data actually fits a different, more robust model—like Catastrophic Plate Tectonics.
By labeling this “conspiratorial,” Rauser is effectively saying that the only rational choice is to never challenge a majority. This is the very definition of historical amnesia.
“Maybe you’re influenced by Thomas Kuhn’s historical understanding of the progress of science and you say ‘all these evolutionists are just locked into a naturalistic paradigm and they can’t see all the evidence for young earth creationism.’ But what that effectively does is it’s going to breed skepticism about expertise generally which is probably going to spill into other areas… in favor of various conspiracy theories.”
Please, reader, take a big gulp of the irony here. There is enough to go around.
The skeptic is worried about skepticism. The very people who will argue that Christianity or theism are ridiculous. The very people who can hold much incredulity to the largest consensus belief in the world are now going to explain why skepticism is a bad methodology.
By warning against skepticism, Rauser is effectively discouraging the very “critical thinking” he claims to promote. To be “critically minded” is, by definition, to be skeptical of claims—especially those that demand uncritical deference.
If an expert cannot explain the data to a thinking layman without resorting to “trust me, I’m an expert,” then their expertise has become a form of sophistry.
Argument #5: The Harmful Belief
“All of this means that allowing young earth creationism to proliferate unchallenged among the evangelical and fundamentalist protestant Christian subculture does enormous damage to the integrity and the witness of Christianity in North America.”
This last point is supremely interesting. Does he think, first of all, that creationism has gone unchallenged in Western society? Even among evangelical and fundamentalist movements, there is a clear pressure to conform to the infallible doctrine of scientism.
Does he think the Christians will gain ground in culture, if we give up ground? Will we convert more to the truth, if we tell lies?
Let’s call out this appeal to the harm of young earth creationism for what it is—eurocentric scientific elitism. This argument only carries weight in the West, and it should really carry weight nowhere, because it is simply not an argument.
Final Thoughts:
Rauser’s case study is a masterclass in Scientism—the belief that the methods and conclusions of the natural sciences are the only source of genuine knowledge. His methodology requires the layman to be a passive consumer of institutional output rather than an active, critical thinker.
By deconstructing his arguments, we’ve shown that:
His history is socially contingent and misses the broader tradition and trends.
His “Expert Appeal” is circular and ignores the history of scientific revolutions.
His “Lecture Test” is elitist gatekeeping which ignores how we evaluate data.
His “Harm” argument prioritizes social comfort over consistency and truth.
To summarize, we should evaluate each model based on the evidence, parsimony, predictive success, presuppositions, coherence, consilience, etc—take your pick. We should not be evaluating the models on external factors such as perceived harm, individual comprehension, appeals to consensus, appeals to experts, and appeals to novelty or social contingency. These in the latter list do not help us in the project of “how to think.” And the project of “who to trust” has always been a very dangerous game.
The Created Heterozygosity and Natural Processes (CHNP) model, proposed by Nathaniel Jeanson (Jeanson, 2016), suggests that a significant amount of genetic diversity in originally created organisms was frontloaded rather than accumulating slowly through random mutations. Implicit in Jeanson’s model is the postulate that all diversity in humankind has emerged from two biallelic individuals. Little work has been done to explicate original allelic morphologies in created kinds, therefore this study will address this gap in the CHNP model by identifying functional genes (the frontloaded heterozygosity) and their deleterious variants. This study also aims to give quantified rates of mutations necessary for novel allelic frequencies. Doing so allowed for testing the two primary predictions of the CHNP model: (1) Mutations accumulate at a semi-constant rate, and are sufficient to explain novel diversity beyond the initial biallelic kinds and (2) initial created kinds were highly functional and optimized, containing no non-functional or suboptimal gene variants, therefore only function will be shared across lineages. We analyzed a variety of gene families (including CLLU1, MHC, LCT, ABO, Rh, KIR, NANOG, AMY1, DARC, GULO, and FOXP2) and found that initial functional alleles are highly conserved across species, while loss-of-function alleles are species-specific. Balancing selection reveals conflicting and contradictory hypotheses for the origin of alleles leading to the evolutionary explanations becoming ad hoc. The observed mutation rates for diversification of original biallelic pairs falls in the estimated 6000-year timeframe. These findings dovetail with prior CHNP research for known modern rates of molecular clock data (Jeanson, 2019). The results of this data are best explained by the CHNP model, as these genes produce young, discontinuous phylogenetic trees which begin with two variants and later branch into homozygosity. The data strongly supports genetic drift, founder effects, and weak selective pressure for all gene families.
Introduction
The key tenets of CHNP are frontloaded genetic diversity followed by rapid diversification into more homozygous populations via recombination, genetic drift, and regulatory mechanisms all amplified by major and minor founder effects. In CHNP, mutations are seen as creating new allelic variation by degrading the optimized biallelic state in various ways. CHNP, therefore, follows the principles of genetic entropy (GE) and chemical laws (Sanford, 2008). The selected gene families support this view as well as known chemical and structural mutation hot spots. The assumption of design is taken for granted in this paper, however much research has been done to support this inference and the problem of the insufficiency of naturalistic processes (Axe, 2004; Meyer, 2004; Meyer, 2021; Nelson & Buggs, 2016; Thorvaldsen & Hössjer, 2020). CHNP provides a coherent alternative framework to explain the abundance of genotypic and phenotypic diversity we observe in the biological world by emphasizing a pre-existing, divinely-created potential for variation, which is then expressed and refined through natural processes over a much shorter timeframe than mainstream evolutionary models propose.
Being a relatively new evolutionary framework (a little over a decade old), CHNP has yet to elucidate particular historical details such as the evolution of the diversity of alleles. This has led to some popular-level critiques from well-meaning skeptics of the model making serious errors in their assessments (Duff, 2023; Hancock, 2023). Questions have been raised along the lines of: (1) How does CHNP account for the wide diversity and sheer number of alleles in modern human populations, when Adam and Eve could only account for a maximum of four alleles? (2) How does a human population maintain this initial variation of a biallelic couple over generations and then increase in variation? This paper successfully accounts for both challenges: There is overwhelming evidence that all the diversity at different loci for human alleles can be explained by two original humans with the same bi-allelic autosomes. The disparity (divergence in morphospace) and diversity (increase in morphologies) is then created by both homologous recombination and mutational load/GE, respectively.
Works Cited
Axe, Douglas D. “Estimating the Prevalence of Protein Sequences Adopting Functional Enzyme Folds.” Journal of Molecular Biology, vol. 341, no. 5, Aug. 2004, pp. 1295–1315, https://doi.org/10.1016/j.jmb.2004.06.058.
Meyer, Stephen C. “The Origin of Biological Information and the Higher Taxonomic Categories.” Proceedings of the Biological Society of Washington, vol. 117, no. 2, 4 Aug. 2004, pp. 213–239. https://www.discovery.org/a/2177/.
Meyer, Stephen C. “The Return of the God Hypothesis: Compelling Scientific Evidence for the Existence of God.” HarperOne, 30 Mar. 2021.
Nelson, Paul A., and Richard J. A. Buggs. “Next Generation Apomorphy: The Ubiquity of Taxonomically Restricted Genes.” Next Generation Systematics, by Paul A. Nelson and Richard J. A. Buggs, Cambridge University Press, 5 June 2016, pp. 237–263. 10.1017/CBO9781139236355.013.
Sanford, John C. “Genetic Entropy & the Mystery of the Genome.” FMS Publications, 2008.
Thorvaldsen, Steinar, & Ola Hössjer. “Using Statistical Methods to Model the Fine-Tuning of Molecular Machines and Systems.” Journal of Theoretical Biology, vol. 501, no. 110352, Sept. 2020, https://doi.org/10.1016/j.jtbi.2020.110352.
Part IV: ABO
The ABO blood group, the first human blood group system discovered, remains a cornerstone of evolutionary biology and anthropology. The standard evolutionary model seeks to explain the persistence of the A, B, and O alleles in human and other primate populations through a concept known as “trans-species polymorphism.” This hypothesis posits that certain alleles are maintained by balancing selection for millions of years, predating speciation events. Consequently, the functional A and B alleles are argued to be approximately 20 million years old, having originated in a common ancestor and been preserved through the evolutionary divergence of modern primate branches (Ségurel et al., 2012). This ancient origin is believed to be the reason why humans, chimpanzees, gorillas, and other primates and mammals share the same genetic basis for the A and B antigens. Some mammals, such as cows, dogs, and cats, which are said to have diverged from the primate line over 80-90 million years ago, still maintain functional A and B alleles which are said to have been convergently evolved.
1. The Paradox of the ‘O’ Allele
While the A and B alleles are functional—coding for glycosyltransferase enzymes that attach specific sugars to red blood cells—the O allele is non-functional, or “null.” The O phenotype arises from mutations, typically single nucleotide polymorphisms (SNPs) or insertions/deletions (InDels), that introduce a frameshift, resulting in a non-working enzyme. From a molecular perspective, the mutational pathways to a null allele are numerous and common; it is far easier to break a functional gene than to create one.
This molecular reality is coupled with a powerful selective pressure: the O allele confers significant resistance to severe forms of malaria. Given that malaria is a potent selective force in many regions of the world, and that primates have purportedly been evolving in such environments for millions of years, a paradox emerges. If the functional A and B alleles were maintained for 20 million years, then the highly advantageous and mutationally accessible O allele should have appeared constantly throughout this timeframe. Natural selection should have preserved it just as diligently, if not more so, than A and B. The logical prediction of the evolutionary model is, therefore, that the O allele should also be ancient and shared by descent among primate species.
2. Genetic Evidence Falsifies this Evolutionary Prediction
Contrary to the prediction derived from the deep-time model, genetic data reveals the precise opposite. While the functional A and B alleles show evidence of shared ancestry, the non-functional O alleles are demonstrably recent and species-specific. A key study by Ségurel et al. (2012) states this finding unequivocally:
“Thus, primates not only share their ABO blood group, but also the same genetic basis for the A/B polymorphism. O alleles, in contrast, result from loss-of-function alleles such as frame-shift mutations and appear to be species specific.”
Another paper researching non-primate ABO polymorphisms, from Kermarrec et al. (2017), wrote:
“The sequences of cDNAs corresponding to the chimpanzee and rhesus monkey O alleles were characterized from exon 1 to 7 and from exon 4 to 7, respectively. A comparison of our results with ABO gene sequences already published by others demonstrates that human and non-human primate O alleles are species-specific and result from independent silencing mutations. These observations reinforce the hypothesis that the maintenance of the ABO gene polymorphism in primates reflects convergent evolution more than transpecies inheritance of ancestor alleles.”
This means the specific mutations that create the O allele in humans are different from the mutations that create the O allele in chimpanzees, which are different from those in bonobos, orangutans, gorillas, etc. This is definitive proof that the O allele is not shared from a common ancestor. Instead, its appearance is convergent, having arisen independently in each lineage. The central question remains: if the O allele is so advantageous and easy to make, why did it not appear and become fixed or conserved anciently?
Evolutionary genetics has proposed several auxiliary hypotheses to resolve this paradox, none of which withstand scrutiny:
The Pathogen Trade-Off Hypothesis:
One proposal is that the O allele was constantly eliminated by negative selection because it confers vulnerability to other pathogens, such as gut bacteria like Vibrio cholerae. However, this is empirically falsified by the existence of entire populations, such as Native Americans, who are nearly 100% Type O and thrived for millennia prior to European contact. This demonstrates that any disadvantage cannot be a universal evolutionary law sufficient to prevent the fixation or preservation of the O allele over tens of millions of years.
The Malaria-Smallpox “Tug-of-War” Hypothesis:
A more complex hypothesis has been invoked to explain the balanced allele frequencies in Europeans, where malaria was endemic but did not seem to exert the same selective pressure. This model suggests a selective “tug-of-war,” with malaria selecting against A and B, while smallpox targeting the foundational H-antigen (most exposed in Type O individuals), thereby selecting for A and B. However, the link between smallpox and blood type is based on conflicting and weak evidence. The foundational studies from the 1960s were heavily criticized by peers as likely reflecting methodological artifacts, while other comprehensive studies found no statistically significant link at all (Downie et al., 1965). Furthermore, genetic analysis of ancient European populations shows the O allele was present prior to widespread agriculture and malaria pressure, and its distribution shows no clear correlation with ancient malaria patterns (Gelabert et al., 2017). Given the challenges and apparent ad hoc nature of these explanations, it is valuable to consider an alternative framework that may account for the data more directly.
3. Phylogenetic Structure and Mutation Counts in ABO
The ABO system’s 345 recognized alleles (ISBT v11, January 2026) form a tree-like phylogeny rooted in an ancestral A-like sequence, with major branches forking via defining core events and subtypes adding derivatives. This structure collapses observed diversity into ~150–200 unique nucleotide changes (mostly SNPs and indels), far fewer than independent origins would require. Functional A and B alleles are conserved across species, while loss-of-function O variants are species-specific, supporting CHNP’s frontloaded heterozygosity.
Table 1: Cumulative Missense Mutations by ABO Phenotype
The table below summarizes missense mutations (amino acid-altering changes) across 207 alleles from a detailed dataset, grouped by phenotype. These represent cumulative instances relative to reference A¹ (ABO*A1.01).
Phenotype Group
# of Alleles
Total Missense Mutations
Avg Mutations per Allele
A Subtypes
A1 (Reference)
2
1
0.5
A2
18
32
1.8
A3
7
10
1.4
A (Weak/Other)*
55
83
1.5
B Subtypes
B (Core)
3
14
4.7
B (Weak/Other)**
46
230
5.0
O Subtypes
O (Null)
62
130
2.1
Hybrids
cis-AB / B(A)
12
42
3.5
TOTAL
207
544
2.6
Note: *Includes Aweak, Ael, Afinn, Am, Ax. **Includes B3, Bel, Bweak, Bx. The low average divergence (2.6 mutations) across hundreds of alleles supports the CHNP view of recent diversification from highly functional progenitors, rather than deep-time accumulation.
Table 2: Cumulative Missense Mutations by ABO Phenotype
Analysis of 207 detailed alleles showing the distribution of amino acid-altering changes relative to the reference A1 allele.
Branch / Clade
Allele Count (Est.)
Core Mutation Events (Defining the Branch)
Derivative Diversity (Unique Events)
Representative Subtypes
Evolutionary Mechanism
A (Ancestral)
~60
0 (Reference State)
~40
A¹, A², A³
Original State: Variations arise via single SNPs (e.g., p.Pro156Leu).
Loss of Function: Dominant inactivation event followed by drift/selection (Malaria).
Hybrids
~35
Chimeric Fusions
~10
cis-AB, B(A)
Recombination: Fusion of A/B cores; not de novo creation of new information.
OVERALL
345
~10 Core Events
~100–150
Parsimony: <200 unique events explain all 345 alleles.
The “Bushy” structure of the tree—short branches radiating from specific cores—aligns with the “Pulse-Fragmentation” model below. The high allele count is an illusion caused by counting slight variants of the same few functional themes.
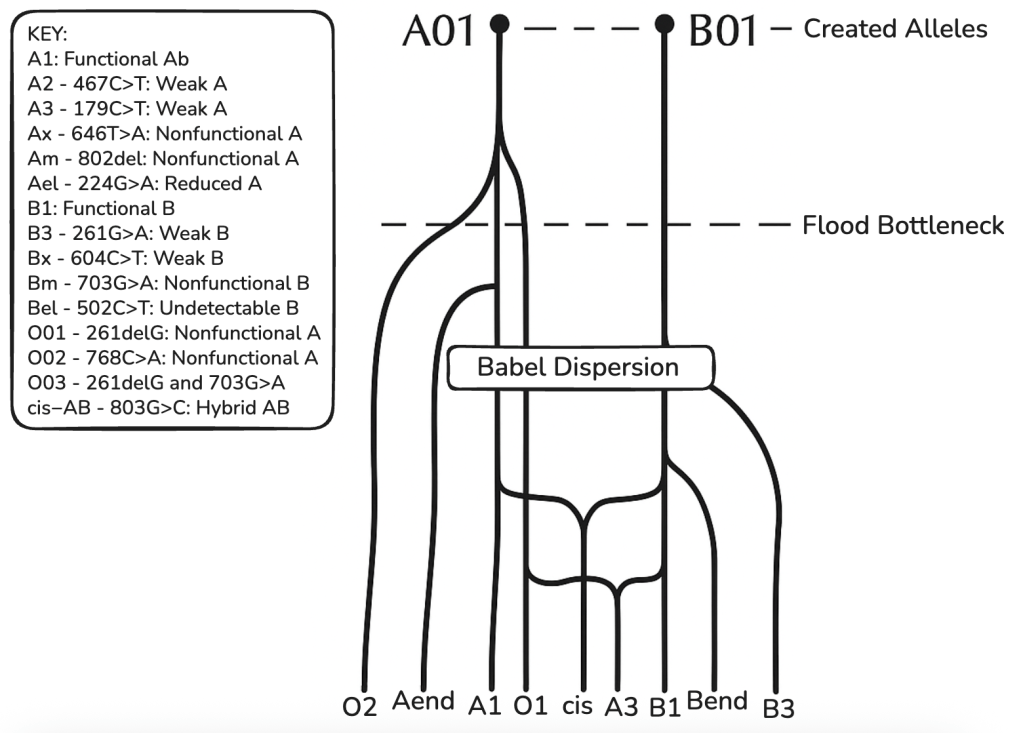
Table 3: ABO Phylogenetic Tree
Above is a phylogenetic tree for the ABO blood group gene based on the CHNP model. Showing several mainline alleles as well as two case bases (cis-AB and A3) which arose from, among other events, intragenic recombination. A-end and B-end represent further variants of weak A or B and O alleles.
This model shows alleles cluster into 6–8 major clades with low divergence (avg. 1.5 nt/allele beyond cores), consistent with young, discontinuous trees.
4. Implications for the CHNP Model
Mutation Budget
To evaluate whether the observed diversity in the ABO gene is consistent with the CHNP model (a ~6,000–10,000 year timeframe), we must calculate the expected number of mutation events using established human mutation rates. The ABO gene spans approximately 24,000 base pairs (24kb). The standard human mutation rate is estimated at 1.1 X 10-8 per base pair per generation (Roach et al., 2010; Campbell et al., 2012).
Traditionally, we analyze this “budget” like so. The number of mutations separating a modern individual from the original ancestor, Lineage Accumulation. In a single direct lineage from a founder (e.g., Adam) to a modern human, the expected number of de novo mutations in the ABO gene is calculated as:
Mutations = Rate (1.1 x 10-8) x Gene Size (24,000) x Generations (low 200 to high 333)
(1.1 x 10-8) x 24,000 x 333 (or 200) ≈ 0.087912 mutations (or 0.528)
A modern individual is expected to differ from the ancestral sequence by less than 0.1 mutations on average.
This indicates that the 127–200 unique variants observed today cannot be the result of accumulation along a single line. They must represent a collection of rare variants preserved from a much larger total inventory of events across the population.
While a single lineage accumulates little change, the population as a whole generates massive diversity due to exponential growth. Modeling a population expansion from a bottleneck of 6 individuals to 8 billion over 333 generations, we can estimate the total number of mutation events that have occurred in the ABO gene history. The total human mutations (genome-wide) are ~4.40 x 1011 (440 Billion) events.
The ABO gene represents ~0.0008% of the genome. For ABO specific events, we calculate 4.40 x 1011 x (24,000 / 3.2 x 109) = 3.3 million events. Therefore, the CHNP model faces a “retention” challenge rather than a “production” challenge. The young human population has generated over 3.3 million mutation events in the ABO gene history, far exceeding the ~200 unique alleles observed today. The vast majority of these 3.3 million events were lost to genetic drift or purifying selection (ABO incompatibility). The presence of ~200 unique alleles is mathematically possible within 6,000 years, provided that these specific variants survived drift.
The observation that most alleles are “subtypes” of A or B (differing by only 1 SNP) is consistent with them being recent survivors from this large pool of 3.3 million historical events. The ABO locus’s genetic diversity—345 alleles arising from ~127–200 unique mutations—must be understood in the context of population-wide mutation loads. While a single lineage accumulates negligible change (<1 mutation), the global human population has generated an estimated 3.3 million mutation events in the ABO locus over the last 10 millennia. The observed ~200 unique variants represent a tiny fraction (<0.01%) of this historical inventory that successfully reached detectable frequencies. This supports a model where the core A and B alleles were frontloaded, while the “bushy” diversity of subtypes (including the various O alleles) arose recently from the vast reservoir of population-wide mutations.
Paternal Age Effect
Standard evolutionary calculations assume a constant mutation rate based on a 20-to-30-year generation time. However, the CHNP model posits distinct biological parameters for the early human population, specifically the extreme longevity of the Patriarchs (e.g., Noah, Shem, Arphaxad). Modern genetic research confirms a strong Paternal Age Effect, where the number of de novo mutations passed to offspring increases exponentially with the father’s age due to continuous cell division in the male germline (Kong et al., 2012).
For example, a 30-year-old father transmits ~45 new mutations. Whereas, if the mutation rate doubles every ~16.5 years of paternal age (as observed in modern humans), a father conceiving at age 100, 200, or 500 would transmit hundreds or potentially thousands of de novo mutations in a single generation.
Table 4: Patriarch Exponential Mutation Curve
Father’s Age at Conception
Standard Model (Total Mutations Transmitted In X Years)
Patriarchal Model (Projected Mutations)*
Impact Factor
30 years (Modern Avg)
~45
~45
1x (Baseline)
63 years
~90 (gen 2)
~180
2x
100 years
~135 (gen 3)
~850
~6x
200 years
~270 (gen 6)
~56,000**
~207x
500 years (e.g., Noah)
~720 (gen 16)
Saturation
Explosive
*Projections based on a doubling of the mutation rate every 16.5 years of paternal age (Kong et al., 2012).**Theoretical projection highlighting the exponential potential of long-lived germlines.
This biological reality suggests that the “Input” of mutations in the first millennium of human history was not linear but explosive. The initial mutation inventory was likely frontloaded by these long-lived progenitors, rapidly diversifying the created template far faster than current low-fidelity rates would predict.
Demographic Accelerants: Inbreeding and Fixation
Following the population bottlenecks (Creation and the Flood), high rates of consanguinity (inbreeding) were unavoidable. While modern population genetics views inbreeding primarily as a mechanism for exposing recessive traits, in the CHNP context, it serves as a powerful evolutionary accelerant in two ways:
Rapid Fixation via Drift: In small, inbreeding populations, the coefficient of genetic drift is high. New mutations—whether generated by patriarchs or random errors—can move from 0% to 100% frequency (fixation) in just a few generations. This overcomes the “swamping” effect seen in large populations, allowing unique ABO variants (like specific O alleles) to become characteristic of entire distinct lineages instantly.
Accumulation of Genetic Load: Inbreeding depresses the effectiveness of purifying selection (“Inbreeding Depression”). Slightly deleterious mutations (such as the degradation of the A antigen into O) are less effectively weeded out in small populations (Lynch et al., 1995). This relaxes the selective constraints, allowing loss-of-function alleles to accumulate and persist at rates that would be impossible in a large, randomly mating population.
The Pulse-Fragmentation Model
When these factors are integrated, the CHNP model predicts a specific pattern:
Pulse: A surge of mutational diversity generated by high-age Patriarchs.
Fragmentation: Rapid isolation of this diversity into distinct gene pools via inbreeding and migration.
Degeneration: The inevitable slide from heterozygous function (A/B) to homozygous dysfunction (O) due to entropic forces.
Additional Considerations
Phylogenetic Tree Structure: ABO’s bushy clades (e.g., weak B from B core + 1–2 missense) exemplify recurrent inheritance, reducing independent events.
Parsimonious Evolutionary Model: <200 uniques suffice for all diversity, aligning with CHNP’s recent, bottlenecked history.
Conclusion
The ABO locus’s genetic diversity—345 alleles arising from ~127–200 unique mutations—is within the expected mutation budget under the CHNP model (~330 events over 10 kyr). The phylogenetic tree structure, with subtypes branching from a handful of core ancestral mutations (e.g., A-to-B divergence), supports a parsimonious evolutionary framework where recurrent propagation explains observed variation. Pre-loaded A and B alleles could plausibly have diversified via neutral drift in a young human population, consistent with CHNP claims. The observed genetic diversity at the ABO locus, with 127 to 200 unique mutations, is within the expected range of mutations under the CHNP model. This indicates that the pre-loaded A and B strings could have been accumulating mutations for around 10 kyr, consistent with the CHNP claim for ABO.
Works Cited
Besenbacher, Søren, et al. “Novel Variation and de Novo Mutation Rates in Population-Wide de Novo Assembled Danish Trios.” Nature, vol. 6, no. 1, 19 Jan. 2015, https://doi.org/10.1038/ncomms6969.
Dean, Laura. “Hemolytic Disease of the Newborn.” Nih.gov, National Center for Biotechnology Information (US), 2005, www.ncbi.nlm.nih.gov/books/NBK2266/.
*Dean, Laura. “The ABO Blood Group.” National Library of Medicine, National Center for Biotechnology Information (US), 2005, www.ncbi.nlm.nih.gov/books/NBK2267/.
Downie, A W, et al. “Smallpox Frequency and Severity in Relation to A, B and O Blood Groups.” Bulletin of the World Health Organization, vol. 33, no. 5, 1965, p. 623, pmc.ncbi.nlm.nih.gov/articles/PMC2475872/.
Gelabert, Pere, et al. “Malaria Was a Weak Selective Force in Ancient Europeans.” Scientific Reports, vol. 7, no. 1, 3 May 2017, https://doi.org/10.1038/s41598-017-01534-5.
Kermarrec, Nathalie, et al. “Comparison of Allele O Sequences of the Human and Non-Human Primate ABO System.” Immunogenetics, vol. 49, no. 6, 5 May 1999, pp. 517–526, https://doi.org/10.1007/s002510050529.
Kong, Augustine, et al. “Rate of de novo mutations and the importance of father’s age to disease risk.” Nature, vol. 488, no. 7412, 2012, pp. 471-475.
Kwiatkowski, Dominic P. “How Malaria Has Affected the Human Genome and What Human Genetics Can Teach Us about Malaria.” The American Journal of Human Genetics, vol. 77, no. 2, Aug. 2005, pp. 171–192, https://doi.org/10.1086/432519.
Lynch, M., et al. “Mutation accumulation and the extinction of small populations.” The American Naturalist, vol. 146, no. 4, 1995, pp. 489-518.
Marian, Jakub. “Blood Type Distribution,” Jakubmarian.com, 2018.
Mullaney, J. M., et al. “Small Insertions and Deletions (INDELs) in Human Genomes.” Human Molecular Genetics, vol. 19, no. R2, 21 Sept. 2010, pp. R131–R136, https://doi.org/10.1093/hmg/ddq400.
Nachman, Michael W, and Susan L Crowell. “Estimate of the Mutation Rate per Nucleotide in Humans.” Genetics, vol. 156, no. 1, 1 Sept. 2000, pp. 297–304, https://doi.org/10.1093/genetics/156.1.297.
O’Neil, Dennis. “Modern Human Variation: Distribution of Blood Types.” Kinsta.page, 2012, anthropology-tutorials-nggs7.kinsta.page/vary/vary_3.htm.
As I have been promoting the Kalam cosmological argument, I’ve been thinking deeply about its particular criticisms. To be clear, most criticisms of Craig’s Kalam fail, however some are fascinating and get you thinking about the particulars such as what existence means and whether ex nihilo (out of nothing) is an ontologically distinct kind of creation which we don’t observe.
On one hand, most proponents of the Kalam are perfectly willing to grant that we don’t observe ex nihilo creation and redirect the skeptic to the metaphysical entailments of creation (usually from the principle of sufficient reason), suggesting that the universe, and all things which have ontology in and of themselves, do need efficient causes. Yet, I really don’t think we need to cede ground here. As I’ve meditated on this, I’ve come to the conclusion that we do in fact observe ex nihilo creations—from our minds.
What do I mean by this? Well, take any concept of a “thing”, let’s say a wooden chair (it’s the favorite of philosophers), and ask ourselves how it is that this thing exists in the “real” world. When we examine a chair carefully, we discover something remarkable: the chair as a unified object—as a chair—does not exist in the physical substrate at all. What exists physically are atoms arranged in a particular configuration. The “chairness” of this arrangement, the ontological unity that makes these atoms one thing rather than billions of separate things, is something imposed by mind. In this sense, we observe minds creating genuine ontological categories ex nihilo—not creating the matter itself, but creating the very thingness that makes a collection of particles into a unified object.
This realization leads to a profound philosophical argument that I believe has been insufficiently explored in contemporary philosophy of religion.
The Nature of Composite Objects
We land on a few interesting features when we examine any purported “thing” in the material world. For one, a thing is instantiated in the world separate from its physical parts. This chair, for instance, may be made of wood, but many metals, plastics, and fabrics can be substituted and the identity of a thing within a category (or genus) is not changed. There is something higher than just mere components which brings the composition into a unified whole.
But what is this “something higher”? The materialist wants to say it’s just the arrangement of particles. But this raises immediate problems. Consider: when exactly does a collection of wood atoms become a chair? When the carpenter has assembled 50% of the pieces? 75%? 90%? What if one leg is broken—is it still a chair, or merely chair-shaped atoms? What if the leg is cracked but still functional? The materialist has no principled answer to these questions because “chairness” is not a property that can be reduced to particle arrangements.
The problem becomes even clearer when we consider boundaries. A chair has clear boundaries to us—we know where the chair ends and the floor begins. But at the atomic level, there are no such boundaries. Atoms are constantly exchanging electrons, being shed and replaced. Air molecules intermingle with the chair’s molecules at the surface. There is no physical demarcation that says “here the chair ends.” The boundaries we perceive (form) are imposed by our minds based on function and purpose.
This leads to several different possible conclusions about where a “thing” must be sustained. We are asking where something really exists, ontologically speaking. To be precise, there are three exhaustive options: (1) the thing is sustained in a domain of itself (like Platonic Forms), (2) the thing is sustained in the material domain (by physics and chemistry alone), (3) the thing is sustained in the mental domain (by a mind). I offer the reader to consider alternate hypotheses and notice that these choices really do cover the gamut.
The Trilemma of Ontology
Let us examine each option in turn to see which can bear the weight of explanation.
Option 1: Material Sustenance (Reductionist Materialism)
For the materialist position, we run into the logical contradiction of unified-composite objects. The materialist must assume that composite objects, like a rock, have no inherent boundaries. Physical things are mere indifferentiable clusters of atoms. From here, the materialist has two options. They can either accept a form of object nihilism, where no composite objects actually exist, or they can turn to a nominalistic approach.
In regards to nominalism, we must ask: what is the reason we would call a rock “rock” if separate from its ontology or it actually being a rock? If things, like a rock, exist in name only, then they do not really exist within distinct categories or kinds. This renders their definitions completely meaningless, because a good definition requires classification within the context of genus-species relationships. If things really exist as distinct objects, it is only because we have determined some aspect of their ontology over and above what reductionism or materialism can explain. So in reality, there is no sustainable nominalist approach for the materialist: one is either an object nihilist, or one must accept that real things are established some other way.
It seems to me that something like a rock is a perfect example of what would be impossible to be established as ontologically distinct without a mind. Is a pebble a rock? Is a handful of sand many small pebbles? Why do we call a variant quantity of small rocks a singular category? Why do we delineate between singular grains of sand and groups of pebbles? Is it not an arbitrary size distinction relative to our observational abilities and purposes?
For another example, consider why people groups such as Inuit tribes, who live in snowy environments, have many particular names for snow, whereas those tribes who live near the equator do not. It is because words are conventions within social groups to establish meaningful concepts. To someone who may see snow one day of the year, different textures and variations of snow are not meaningfully distinct. All composite objects that exist—including the very words that I am writing—are things minds have established as meaningful and bounded.
Therefore, a rock is meaningfully different from a pebble and a group of pebbles from sand only insofar as our use or intent dictates. Our experience of snow presupposes our naming conventions of snow. If you learn a language with seven words for snow, but you have always lived in a desert, you will not suddenly understand snow differently—you need to experience snow differently first.
But the materialist might object: “Even if our labels are arbitrary, the physical arrangements are real. When I sit in a chair, something physical holds me up.” This is true, but it misses the point. Yes, atoms arranged in a certain configuration will bear weight. But those atoms bearing weight is not the same as a chair existing. The chair, as a unified object with identity over time, with the capacity to be the same chair even if we replace parts, with clear boundaries—this is not present in the physical substrate. It is a mental construct imposed on that substrate.
Consider the philosophical puzzle of the Ship of Theseus. If we replace every plank of a ship, one by one, is it the same ship? The puzzle has no answer in purely physical terms because the ship’s identity is not a physical property. Identity over time, unity, and boundaries are all features imposed by minds, not discovered in matter.
If you accept Object Nihilism for composite objects and argue for a fundamental realist view where only quarks and leptons (or quantum fields) exist, then you face equally severe problems. What is your evidence that you exist ontologically? An entity which doesn’t exist as a unified object cannot consistently argue that some things do exist as unified objects. Moreover, what is your basis for assuming you know the “stuff” which is fundamental to reality? Even the quantum field is not necessarily the bottom line. Who can say what energy ultimately is? What’s to say that what’s fundamental isn’t also mind-contingent? That it isn’t mathematical in nature—which would itself require mental grounding?
This view has made a distinction where everything composite is nominal except for something that has never been directly observed as a truly fundamental “thing.” How does one justify this distinction in the first place? It seems to me a contradiction in reasoning to deny mind-dependent categories for composite objects while affirming mind-independent categories for fundamental particles. Both require the same kind of ontological boundary-drawing that only minds can provide.
Option 2: Self-Sustaining Forms (Platonism)
From here, a skeptic might say, “Okay, the chair or rock isn’t purely material. But maybe it’s just a Platonic Form. It sustains itself in an abstract realm. Why do we need a Mind?”
This is a more sophisticated response, but it ultimately fails for several reasons.
First, abstract objects have no causal power. A Platonic Form of “chairness” cannot reach down into the physical world and organize atoms into a chair configuration. It cannot explain why this particular collection of atoms instantiates the form rather than some other collection. The relationship between abstract forms and concrete particulars remains deeply mysterious in Platonic metaphysics—so mysterious that even Plato himself struggled with it in dialogues like the Parmenides.
Second, and more fundamentally, it is unintelligible to think of abstract objects like propositions, mathematical truths, or forms existing without a mind to think them. As Alvin Plantinga has argued, propositions are the contents of thoughts. They are the sort of thing that exists in minds. To say they exist “on their own” in some abstract realm is to commit a category error—it’s like saying colors exist independently of anything colored, or that motion exists independently of anything moving.
Consider what a Platonic Form would have to be: a truth, a concept, a logical structure. But these are precisely the kinds of things that exist as thoughts. A thought cannot exist without a thinker any more than a dance can exist without a dancer. The Platonist wants to affirm that 2+2=4 exists eternally and necessarily, and I agree. But this truth exists as an eternal thought in an eternal mind, not as a free-floating abstraction.
Third, many Platonic forms presuppose relationships, which themselves presuppose minds. Take the concept of justice. Justice involves right relations between persons. But “right relations” is an inherently normative concept that makes no sense without minds capable of recognizing and valuing those relations. Or consider mathematical sets. A set is defined by a rule of membership—a mental act of grouping things together according to a criterion. Sets don’t group themselves.
Therefore, if the “Blueprint” of the universe is real—if there truly are eternal structures, categories, and forms that ground the intelligibility of reality—these cannot be free-floating abstract objects. They must be Divine Thoughts, eternally sustained in a Divine Mind.
Option 3: Mental Sustenance (Idealism)
This leaves us with the third option: composite objects exist insofar as they are sustained by minds. This may sound counterintuitive at first, but it’s the only option that avoids the contradictions of the previous two.
When a carpenter builds a chair, he doesn’t merely arrange atoms—he imposes a conceptual unity on those atoms. He creates boundaries where there were none. He establishes identity conditions (this is one chair, not four separate legs plus a seat plus a back). He determines a function and purpose that gives meaning to the configuration. All of these acts are mental, not physical.
But here’s the crucial question: once the carpenter stops thinking about the chair, does it cease to exist? In one sense, yes—the carpenter’s mind is no longer actively sustaining it. But in another sense, no—the chair continues to be recognized as a chair by other minds. As long as someone conceptualizes those atoms as a unified object called “chair,” it exists as such.
This actually goes back to Bishop George Berkeley’s famous argument: “If a tree falls in the woods and no one is there to hear it, does it make a sound?” In a sense, if we stipulate that there is no wildlife and trees lack the ability to register sound frequencies, the fall really does not make a sound. This is because sound is a perception, a mental phenomenon. There are pressure waves in the air, certainly, but “sound” as we experience it requires a mind to interpret those waves.
However, Berkeley went further than this, and so must we. Berkeley argued that material objects continue to exist when no human observes them because God’s mind perpetually perceives them. I want to make a similar but distinct claim: composite objects, categories, and the conceptual structure that makes reality intelligible all require perpetual mental sustenance. Not just observation, but active ontological grounding.
An analogy may help: consider an author writing a novel. The characters in the novel have a kind of existence—they’re not nothing. But their existence is entirely dependent on the author’s creative act and the mind of any reader engaging with them. If every copy of the book were destroyed and everyone forgot the story, the characters would cease to exist in any meaningful sense. They have no “existential inertia” apart from minds sustaining them.
I propose that composite objects in our world are similar. The atoms may have mind-independent existence (though even this is debatable), but the chairness—the unified object with boundaries, identity, and purpose—exists only in minds. And since these objects continue to exist even when finite human minds aren’t thinking about them, they must be sustained by an infinite, omnipresent Mind.
The Formal Argument
All this contemplation leads me to the first formulation of a new kind of contingency argument which I call the Argument from Ontological Sustenance (or Idealist Argument from Contingency):
Premise 1: All composite objects require a mind to sustain their ontology.
Premise 2: The universe is a composite object.
Conclusion: Therefore, the universe requires a mind to sustain its ontology.
This is a logically valid argument, meaning if the premises are true, the conclusion must be as well.
The first premise has been defended at length above. The key insight is that composite objects—things made of parts organized into a unity—have no ontological status in the physical substrate alone. Their unity, boundaries, and identity exist only as mental constructs.
The second premise should be relatively uncontroversial. The universe is composed of parts (galaxies, stars, planets, particles) organized into a whole. It has boundaries (even if those boundaries are the limits of spacetime itself). It has an identity that persists through time. All of these features require the same kind of mental grounding that chairs and rocks require.
Therefore, the universe itself must be sustained in its existence as a unified, bounded entity by a mind. And since the universe contains all finite minds, this sustaining mind must be transcendent—beyond the universe, not part of it.
Why Not Pantheism?
An obvious objection arises: couldn’t the universe itself be the Mind that sustains all these categories? This would be a pantheistic solution—identifying God with the universe itself rather than positing a transcendent deity.
This fails for several reasons:
Step 1: A mind is a container for concepts. It is the sort of thing that has thoughts, holds ideas, and maintains logical relationships between propositions.
Step 2: Necessary truths (logic, mathematics, metaphysics) exist outside our finite minds. We discover them; we don’t invent them. This implies a Greater Mind contains them.
Step 3: Could this Greater Mind be the Universe itself?
Refutation: No. A “Universe Mind” would be composed of parts (galaxies, energy fields, quantum states) and subject to entropy (time, change, decay). But anything composed of parts is contingent—dependent on those parts and their organization. Anything subject to entropy requires external sustenance or an explanation for why it continues to exist through change.
Moreover, the universe is precisely the kind of composite object that needs mental grounding. To say the universe grounds its own categories is circular—it’s like saying a novel writes itself, or a dance choreographs itself.
Conclusion: The Ultimate Sustainer cannot be the Universe. It must be Transcendent (distinct from creation) and Non-Contingent (self-existent, not dependent on anything external to itself).
The Divine Attributes
Once we establish that a Transcendent, Non-Contingent Mind sustains all reality, we can derive further attributes through the classical logic of Act and Potency (pure actuality).
Premise: A Non-Contingent Mind has no external cause, and therefore no external limitations or deficiencies. It is “Pure Act”—fully realized, with no unrealized potential.
Omnipotence
To possess “some” power but not “all” power is to have a limitation—an unrealized potential to do more. But a Non-Contingent Being has no unrealized potentials by definition. Nothing external limits what it can do. Therefore, it possesses all power—omnipotence.
Omniscience
Ignorance is a lack, a privation of knowledge. A Fully Realized Mind has no lacks or privations. Moreover, if this Mind sustains all reality through its thoughts, it must know everything it sustains—otherwise, how could it sustain it? Therefore, it knows all things—omniscience.
Omnibenevolence
Evil, in the classical metaphysical tradition, is a privation—a lack of goodness or being. It is not a positive reality but an absence, like cold is the absence of heat or darkness the absence of light. Since this Mind is Fully Realized Being with no privations, it contains no evil. It is Pure Goodness—omnibenevolence.
Eternity and Immutability
Change implies potentiality—the ability to become something one is not yet. But a Non-Contingent Being has no potentiality. Therefore, it does not change. It exists eternally in a timeless present, not subject to temporal succession.
Personhood
This Mind thinks, knows, and creates categories. These are the activities of a person, not an impersonal force. Moreover, the categories it sustains include moral values, relational properties, and purposes—all of which presuppose personhood. Therefore, this Being is personal.
The Christian Specificity
We have now established the existence of a Transcendent, Omnipotent, Omniscient, Omnibenevolent, Eternal, Personal Mind that sustains all reality. This is recognizably the God of classical theism. But can we go further and identify this God with the specific God of Christianity?
The Argument from Relational Necessity
Premise 1: A God who is Personal, Truthful, and Loving is inherently Relational. Love seeks connection; truth seeks to be known; personhood seeks communion.
Premise 2: To be fully known and to establish a perfect relationship with finite creatures, this Infinite God must bridge the ontological gap. He cannot remain purely transcendent and abstract.
Consider: if God is perfectly loving, His love must be expressed, not merely potential. If God is truth, He must reveal Himself, not remain hidden. If God is personal, He must enter into relationship with persons He has created. But finite creatures cannot reach up to an infinite God—the ontological distance is too vast. Therefore, God must reach down to us.
The Filter
With this criterion, we can evaluate the world’s major religious traditions:
Deism/Pantheism: These fail immediately because they offer no relationship. Deism presents a God who creates and withdraws. Pantheism identifies God with the universe, making genuine relationship impossible.
Unitarian Monotheism (Islam/Judaism): These traditions affirm God’s transcendence and offer prophetic revelation—books and laws sent from on high. But God remains fundamentally separate. He sends messages but does not cross the boundary to unite with creation. The relationship is external, mediated through texts and commandments, never achieving full intimacy or union.
Christianity: This succeeds as the only worldview where the Sustainer becomes the Sustained. In the doctrine of the Incarnation, God doesn’t merely send a message about Himself—He enters history as a human being. The Infinite becomes finite. The Creator becomes a creature. The Mind that sustains all reality subjects Himself to the very categories He created.
This is not merely unique—it’s philosophically necessary. If God is to bridge the ontological gap between infinite and finite, between Creator and creature, He must do so by becoming both. The Incarnation is the only way for perfect relationship to be achieved.
Verification Through Human Experience
The Christian worldview also uniquely and truthfully describes the human condition. We experience ourselves as simultaneously possessing great dignity (made in God’s image, capable of reason and love) and great depravity (prone to selfishness, cruelty, and irrationality). We long for meaning, purpose, and redemption, yet find ourselves unable to achieve these on our own.
Christianity explains this through the doctrine of the Fall and offers a solution through Redemption—not by our own efforts, but by God’s gracious action in Christ. This narrative aligns with both our philosophical conclusions about God’s nature and our existential experience of ourselves.
Conclusion
The Mind that sustains the rock, the chair, and every composite object in reality is the same Mind that entered the world as Jesus of Nazareth. From the seemingly simple question “What makes a chair a chair?” we have traced a path to the central truth of Christianity: God is not distant or abstract, but intimately involved in every aspect of reality, from the smallest pebble to the vast cosmos, from the categories that make thought possible to the incarnate life that makes redemption possible.
This is the Argument from Ontological Sustenance. Like all philosophical arguments, it invites scrutiny, challenges, and further refinement. But I believe it opens a fruitful path for natural theology—one that begins not with cosmological speculation about the universe’s beginning, but with careful attention to the ontological structure of everyday objects and the categories that make them intelligible.
Every time we recognize a chair as a chair, a rock as a rock, or the universe as a cosmos, we are implicitly acknowledging the work of the Divine Mind that makes such recognition possible.
Evolution by natural selection is a foundational theory in biology, observable in bacteria developing resistance, finch beak size changes, and populations adapting to environments. These microevolution examples are experimentally verified and widely accepted.
A deeper question persists: Are the mechanisms of random mutation and natural selection sufficient to explain not only the modification of existing biological structures, but also their original creation? Specifically, can the processes observed in generating variation within species account for the origin of entirely novel protein folds, enzymatic functions, and the fundamental molecular machinery of life?
This essay addresses this question by systematically evaluating the proposed mechanisms for evolutionary innovation, identifying their constraints, and highlighting what appears to be a fundamental limit: the origin of complex protein architecture.
Part I: The Mechanisms of Modification
Gene Duplication: Copy, Paste, Edit
The most commonly cited mechanism for evolutionary innovation is gene duplication. The logic is straightforward: when a gene is accidentally copied during DNA replication, the organism now has two versions. One copy maintains the original function (keeping the organism alive), while the redundant copy is “free” to mutate without immediate lethal consequences.
In theory, this freed copy can acquire new functions through random mutation—a process called neofunctionalization. Over time, what was once a single-function gene becomes a gene family with diverse, related functions.
This mechanism is real and well-documented. For instance, in “trio” studies (father, mother, child), we regularly see de novo copy number variations (CNVs). Based on this, we can trace gene families back through evolutionary history and see convincing evidence of duplication events. However, gene duplication has important limitations:
Dosage sensitivity: Cells operate as finely tuned chemical systems. Doubling the amount of a protein often disrupts this balance, creating harmful or even lethal effects. The cell isn’t simply tolerant of extra copies—duplication frequently imposes an immediate cost.
Subfunctionalization: Rather than one copy evolving a bold new function, duplicate genes more commonly undergo subfunctionalization—they degrade slightly and split the original function between them. What was once done by one gene is now accomplished by two, each doing part of the job. This adds genomic complexity but doesn’t create novel capabilities.
The prerequisite problem: Most fundamentally, gene duplication requires a functional gene to already exist. It’s a “copy-paste-edit” mechanism. It can explain variations on a theme—how you get a family of related enzymes—but it cannot explain the origin of the first member of that family.
Evo-Devo: Rewiring the Switches
Evolutionary developmental biology (evo-devo) revealed something crucial: many major morphological changes don’t come from inventing new genes, but from rewiring when and where existing genes are expressed. Mutations in regulatory elements—the “switches” that control genes—can produce dramatic changes in body plans.
A classic example: the difference between a snake and a lizard isn’t that snakes invented fundamentally new genes. Rather, mutations in regulatory regions altered the expression patterns of Hox genes (master developmental regulators), eliminating limb development while extending the body axis.
This mechanism helps explain how evolution can produce dramatic morphological diversity without constantly inventing new molecular parts. But it has clear boundaries:
The circuitry prerequisite: Regulatory evolution presupposes the existence of a sophisticated, modular regulatory network—the Hox genes themselves, enhancer elements, transcription factor binding sites. This network is enormously complex. Evo-devo explains how to rearrange the blueprint, but not where the drafting tools came from.
Modification, not creation: You can turn genes on in new places, at new times, in new combinations. You can lose structures (snakes losing legs). But you cannot regulatory-mutate your way to a structure whose genetic basis doesn’t already exist. You’re rearranging existing parts, not forging new ones.
Exaptation: Shifting Purposes
Exaptation describes how traits evolved for one function can be co-opted for another. Feathers, possibly first used for insulation or display, were later recruited for flight. Swim bladders in fish became lungs in land vertebrates.
This is an important concept for understanding evolutionary pathways—it explains how structures can be preserved and refined even when their ultimate function hasn’t yet emerged. But exaptation is a description of changing selective pressures, not a mechanism of generation. It tells us how a trait might survive intermediate stages, but not how the physical structure arose in the first place.
Part II: The Hard Problem—De Novo Origins
The mechanisms above all share a common feature: they are remixing engines. They shuffle, duplicate, rewire, and repurpose existing genetic material. This works brilliantly for generating diversity and adaptation. But it raises an unavoidable question: Where did the original material come from?
This is where the inquiry becomes more challenging.
De Novo Gene Birth: From Junk to Function?
To tackle this question, we examine the hypothesis that new genes can arise from previously non-coding “junk” DNA—an idea central to de novo gene birth.
One hypothesis is that non-coding DNA—sometimes called “junk DNA”—occasionally gets transcribed randomly. If a random mutation creates an open reading frame (a start codon, some codons, a stop codon), you might produce a random peptide. Perhaps, very rarely, this random peptide does something useful, and natural selection preserves and refines it.
This mechanism has some support. We do see “orphan genes” in various lineages—genes with no clear homologs in related species, suggesting recent origin. When we examine these orphan genes, many are indeed simple: short, intrinsically disordered proteins with low expression levels.
But here’s where we hit the toxicity filter—a fundamental physical constraint.
The Toxicity Filter
Protein synthesis is energetically expensive, consuming up to 75% of a growing cell’s energy budget. When a cell produces a protein, it’s making an investment. If that protein immediately misfolds and gets degraded by the proteasome, the cell has just run a futile cycle—burning energy to produce garbage.
In a competitive environment (which is where natural selection operates), a cell wasting energy on useless proteins will be outcompeted by leaner, more efficient cells. This creates strong selection pressure against expressing random, non-functional sequences.
It gets worse. Cells have a limited capacity for handling misfolded proteins. Chaperone proteins help fold new proteins correctly, and the proteasome system degrades those that fail. But these are finite resources. If a cell produces too many difficult-to-fold or misfolded proteins, it triggers the Unfolded Protein Response (UPR).
The UPR is an emergency protocol. Initially, the cell tries to fix the problem—producing more chaperones, slowing translation. But if the stress is too severe, the UPR switches from “repair” to “abort”: the cell undergoes apoptosis (programmed cell death) to protect the organism.
This creates a severe constraint: natural selection doesn’t just fail to reward complex random sequences—it actively punishes them. The toxicity filter eliminates complex precursors before they have a chance to be refined.
The Result
The “reservoir” of potentially viable de novo genes is therefore biased heavily toward simple, disordered, low-expression peptides. These can slip through because they don’t trigger the toxicity filters. They don’t misfold (because they don’t fold), and at low expression, they don’t drain significant resources.
This explains the orphan genes we observe: simple, disordered, regulatory, or binding proteins. But it fails to explain the origin of complex, enzymatic machinery—proteins that require specific three-dimensional structures to catalyze reactions.
Part III: The Valley of Death
To understand why complex enzymatic proteins are so difficult to generate de novo, we need to examine what makes them different from simple disordered proteins.
Two Types of Proteins
Intrinsically Disordered Proteins (IDPs) are floppy, flexible chains. They’re rich in polar and charged amino acids (hydrophilic—“water-loving”). These amino acids are happy interacting with water, so the protein doesn’t collapse into a compact structure. IDPs are excellent for binding to other molecules (they can wrap around things) and for regulatory functions (they’re flexible switches). They’re also relatively safe—they don’t aggregate easily.
Folded Proteins, by contrast, have a hydrophobic core. Water-hating amino acids cluster in the center of the protein, away from the surrounding water. This hydrophobic collapse creates a stable, specific three-dimensional structure. Folded proteins can do things IDPs cannot: precise catalysis requires holding a substrate molecule in exactly the right geometry, which requires a rigid, well-defined active site pocket.
The problem is that the “recipe” for these two types of proteins is fundamentally different. You can’t gradually transition from one to the other without passing through a dangerous intermediate state.
The Sticky Globule Problem
Imagine trying to evolve from a safe IDP to a functional folded enzyme:
Start: A disordered protein—polar amino acids, floppy, safe.
Intermediate: As you mutate polar residues to hydrophobic ones, you don’t immediately get a nice folded structure. Instead, you get a partially hydrophobic chain—the worst of both worlds. These “sticky globules” are aggregation-prone. They clump together like glue, forming toxic aggregates.
End: A properly folded protein with a hydrophobic core and stable structure
The middle step—the sticky globule phase—is precisely what the toxicity filter eliminates most aggressively. These partially hydrophobic intermediates are the most dangerous type of protein for a cell.
This creates what we might call the Valley of Death: a region of sequence space that is selected against so strongly that random mutation cannot cross it. To get from a safe disordered protein to a functional enzyme, you’d need to traverse this valley—but natural selection is actively pushing you back.
Catalysis Requires Geometry
There’s a second constraint. Catalysis—the acceleration of chemical reactions—almost always requires a precise three-dimensional pocket (an active site) that can:
Position the substrate molecule correctly.
Stabilize the transition state.
Shield the reaction from water (in many cases)
A floppy disordered protein is excellent for binding (it can wrap around things), but terrible for catalysis. It lacks the rigid geometry needed to precisely orient molecules and stabilize reaction intermediates.
This means the “functional gradient” isn’t smooth. You can evolve binding functions with IDPs. You can evolve regulatory functions. But to evolve enzymatic function, you need to cross the valley—and the valley actively resists crossing.
Part IV: The Escape Route—And Its Implications
There is one clear escape route from the Valley of Death: don’t cross it at all.
Divergence from Existing Folds
If you already have a stable folded protein—one with a hydrophobic core and a defined structure—you can modify it safely:
Duplicate it: Now you have a redundant copy.
Keep the core: The hydrophobic core (the “dangerous” part) stays conserved. This maintains structural stability.
Mutate the surface: The active site is usually on flexible loops outside the core. Mutate these loops to change substrate specificity, reaction type, or regulation.
This mechanism is well-documented. It’s how modern enzyme families diversify. You get proteins that are functionally very different (digesting different substrates, catalyzing different reactions) but structurally similar—variations on the same fold.
Critically, you never cross the Valley of Death because you never dismantle the scaffold. You’re modifying an existing, stable structure, not building one from scratch.
The Primordial Set
This escape route, however, comes with a profound implication: it presupposes the fold already exists.
If modern enzymatic diversity arises primarily through divergence from existing folds rather than de novo generation of new folds, where did those original folds come from?
The empirical data suggest a striking answer: they arose very early, and there hasn’t been much architectural innovation since.
When we examine protein structures across all domains of life, we don’t see a continuous spectrum of novel shapes appearing over evolutionary time. Instead, we see roughly 1,000-10,000 basic structural scaffolds (fold families) that appear again and again. A bacterial enzyme and a human enzyme performing completely different functions often share the same underlying fold—the same basic architectural plan.
Comparative genomics pushes this pattern even further back. The vast majority of these fold families appear to have been present in LUCA—the Last Universal Common Ancestor—over 3.5 billion years ago.
The implication is stark: evolution seems to have experienced a “burst” of architectural invention right at the beginning, and has spent the subsequent 3+ billion years primarily as a remixer and optimizer, not an architect of fundamentally new structures.
Part V: The Honest Reckoning
We can now reassess the original question: Are the mechanisms of mutation and natural selection sufficient to explain not just the modification of life, but its origination?
What the Mechanisms Can Do
The neo-Darwinian synthesis is extraordinarily powerful for explaining:
Optimization: Taking an existing trait and refining it
Diversification: Creating variations on existing themes
Adaptation: Adjusting populations to new environments
Loss: Eliminating unnecessary structures
Regulatory rewiring: Changing when and where genes are expressed
These mechanisms are observed, experimentally verified, and sufficient to explain the vast majority of biological diversity we see around us.
What the Mechanisms Struggle With
The same mechanisms face severe constraints when attempting to explain:
The origin of novel protein folds: The Valley of Death makes de novo generation of complex, folded, enzymatic proteins implausible under cellular conditions.
The origin of the primordial set: The fundamental protein architectures that all modern life relies on
The origin of the cellular machinery: DNA replication, transcription, translation, and error correction systems that evolution requires to function
A New Theory
The constraints we’ve examined—the toxicity filter, the Valley of Death, the thermodynamics of protein folding—are not “research gaps” that might be closed with more data. They are physical constraints rooted in chemistry and bioenergetics.
Modern evolutionary mechanisms are demonstrably excellent at working with existing complexity. They can shuffle it, optimize it, repurpose it, and elaborate on it in extraordinary ways. The diversity of life testifies to its power.
But when we trace the mechanisms back to their foundation—when we ask how the original protein folds arose, how the first enzymatic machinery came to be—we encounter a genuine boundary.
The thermodynamics that make de novo fold generation implausible today presumably existed 3.5 billion years ago as well. Perhaps early Earth conditions were radically different in ways that bypassed these constraints—different chemistry, mineral catalysts, an RNA world with different rules. Perhaps there are mechanisms we haven’t yet discovered or understood.
But based on what we currently understand about the mechanisms of evolution and the physics of protein folding, the honest answer to “how did those original folds arise?” is:
They didn’t.
We need a new explanation that can account for the data. We have excellent, mechanistic explanations for how life diversifies and adapts. We have a clear understanding of the constraints that limit those mechanisms. And we have an unsolved problem at the foundation.
The question remains open: not as a gap in data, but as a gap in mechanism. So what mechanism can account for genetic diversity?
Part VI: A More Parsimonious Model
For over a century, the primary explanation for the vast diversity of life on Earth has been the slow accumulation of mutations over millions of years, filtered by natural selection. However, there is another account of the origins of life that is often left unacknowledged and dismissed as pseudoscience. The concept is simple. We see information in the form of DNA, which is, by nature, a linguistic code. Codes require minds in our repeated and uniform experience. If our experience truly tells us that evolutionary mechanisms cannot account for information systems, as we’ve discovered through this inquiry, then it stands to reason that a design solution cannot rightly be said to be “off the table.
However, there are many forms of design, so which one fits the data?
The answer lies in a powerful, testable model known as Created Heterozygosity and Natural Processes (CHNP). This model suggests that a designer created organisms not as genetically uniform clones, but with pre-existing genetic diversity “front-loaded” into their genomes.
Here is why Created Heterozygosity makes scientific sense.
A common objection to any form of young-age design model is that two people cannot produce the genetic variation seen in seven billion humans today. Critics argue that we would be clones. However, this objection assumes Adam and Eve were genetically homozygous (having two identical DNA copies).
If Adam and Eve were created with heterozygosity—meaning their two sets of chromosomes contained different versions of genes (alleles)—they could possess a massive amount of potential variation.
The Power of Recombination
We observe in biology that parents pass on traits through recombination and gene conversion. These processes shuffle the DNA “deck” every generation. Even if Adam and Eve had only two sets of chromosomes each, the number of possible combinations they could produce is mind-boggling.
If you define an allele by specific DNA positions rather than whole genes, two individuals can carry four unique sets of genomic information. Calculations show that this is sufficient to explain the vast majority of common genetic variants found in humans today without needing millions of years of mutation. In fact, most allelic diversity can be explained by only two “major” alleles.
In short, the problem isn’t that two people can’t produce diversity; it’s that critics assume the starting pair had no diversity to begin with.
Part VI: A Dilemma, a Ratchet, and Other Problems
Before we go further in-depth in our explanation of CHNP, we must realise the scope of the problems with evolution. It is not just that the mechanisms are insufficient for creating novelty, that would be one thing. But we see there are insurmountable “gaps” everywhere you turn in the modern synthesis.
The “Waiting Time” Problem
The evolutionary model relies on random mutations to generate new genetic information. However, recent numerical simulations reveal a profound waiting time problem. Beneficial mutations are incredibly rare, and waiting for specific strings of nucleotides (genetic letters) to arise and be fixed in a population takes far too long.
For example, establishing a specific string of just two new nucleotides in a hominin population would take an average of 84 million years. A string of five nucleotides would take 2 billion years. There simply isn’t enough time in the evolutionary timeline (e.g., 6 million years from a chimp-like ancestor to humans) to generate the necessary genetic information from scratch.
Haldane’s Dilemma
In 1957, the evolutionary geneticist J.B.S. Haldane calculated that natural selection is not free; it has a biological “cost”. For any specific genetic variant (mutation) to increase in a population, the individuals without that trait must effectively be removed from the gene pool—either by death or by failing to reproduce.
This creates a dilemma for the evolutionary narrative:
A population only has a limited surplus of offspring available to be “spent” on selection. If a species needs to select for too many traits at once, or eliminate too many mutations, the required death rate would exceed the reproductive rate, driving the species to extinction.
Haldane calculated that for a species with a low reproductive rate like humans, the cost of fixing just one beneficial mutation would require roughly 300 generations. This speed is far too slow to explain the complexity of the human genome, even within the evolutionary timescale of millions of years.
Rarity of Function
From the perspective of Dr. Douglas Axe, a molecular biologist and Director of the Biologic Institute, there is a mathematically fatal challenge to the Darwinian narrative. His research focuses on the “rarity of function”—specifically, how difficult it is to find a functional protein sequence among all possible combinations of amino acids.
Proteins are chains of amino acids that must fold into precise three-dimensional shapes to function. There are 20 different amino acids available for each position in the chain. If you have a modest protein that is 150 amino acids long, the number of possible arrangements is 20^150. This number is roughly 10^195. To put this in perspective, there are only about 10^80 atoms in the entire observable universe.
The “search space” of possible combinations is unimaginably vast. Evolutionary theory assumes that “functional” sequences (those that fold and perform a task) are common enough that random mutations can stumble upon them. Dr. Axe tested this assumption experimentally using a 150-amino-acid domain of the beta-lactamase enzyme. In his seminal 2004 paper published in the Journal of Molecular Biology, Axe determined the ratio of functional sequences to non-functional ones.
He calculated that the probability of a random sequence of 150 amino acids forming a stable, functional fold is approximately 1 in 10^77. This rarity is catastrophic for evolution. To find just one functional protein fold by chance would be like a blindfolded man trying to find a single marked atom in the entire Milky Way galaxy. Because functional proteins are so isolated in sequence space, natural selection cannot help “guide” the process.
Natural selection only works after a function exists. It cannot select a protein that doesn’t work yet. Axe describes functional proteins as tiny, isolated islands in a vast sea of gibberish. This is precisely the Valley of Death we discussed earlier. You cannot “gradually” evolve from one island to another because the space between them is lethal (non-functional). Even if the entire Earth were covered in bacteria dividing rapidly for 4.5 billion years, the total number of mutational trials would be roughly 10^40. This is nowhere near the 10^77 trials needed to statistically guarantee finding a single new protein fold.
Muller’s Ratchet
While Haldane highlighted the cost and Axe showed the scale, Muller showed the trajectory. Muller’s Ratchet describes the mechanism of irreversible decline. The genome is not a pool of independent genes; it is organized into “linkage blocks”—large chunks of DNA that are inherited together.
Because beneficial mutations (if they occur) are physically linked to deleterious mutations on the same chromosome segment, natural selection cannot separate them. As deleterious mutations accumulate within these linkage blocks, the overall genetic quality of the block declines. Like a ratchet that only turns one way, the damage locks in. The “best” class of genomes in the population eventually carries more mutations than the “best” class of the previous generation. Over time, every linkage block in the human genome accumulates deleterious mutations faster than selection can remove them. There is no mechanism to reverse this damage, leading to a continuous, downward slide in genetic information.
Genetic Entropy
According to Dr. Sanford, these factors together create a lethal dilemma for the standard evolutionary model. The combination of high mutation rates, vast fitness landscapes, the high cost of selection, and physical linkage ensures that the human genome is rusting out like an old car, losing information with every generation.
If humanity had been accumulating mutations for millions of years, our genome would have already reached “error catastrophe,” and we would be extinct. Alexey Kondrashov described this phenomenon in his paper, “Why Have We Not Died 100 Times Over?” The fact that we are still here suggests we have only been mutating for thousands, not millions, of years.
The vast majority of mutations are harmful or “nearly neutral” (slightly harmful but invisible to natural selection). These mutations accumulate every generation. Human mutation rates indicate we are accumulating about 100 new mutations per person per generation. If humanity were hundreds of thousands of years old, we would have gone extinct from this genetic load.
Created Heterozygosity aligns with this reality. It posits a perfect, highly diverse starting point that is slowly losing information over time, rather than a simple starting point struggling to build information against the tide of entropy. The observed degeneration is also consistent with the Biblical account of a perfect Creation that was subjected to corruption and decay following the Fall.
Rapid Speciation
Proponents of CHNP do not believe in the “fixity of species.” Instead, they observe that species change and diversify over time—often rapidly. This is called “cis-evolution” (diversification within a kind) rather than “trans-evolution” (changing from one kind to another).
Speciation often occurs when a sub-population becomes isolated and loses some of its initial genetic diversity, shifting from a heterozygous state to a more homozygous state. This reveals specific traits (phenotypes) that were previously hidden (recessive). These changes will inevitably make two populations reproductively isolated or incompatible over several generations. This particular form of speciation is sometimes called Mendelian speciation.
Real-world examples of this can easily be found. We see this in the rapid diversification of cichlid fish in African lakes, which arose from “ancient common variations” rather than new mutations. We also see it in Darwin’s finches, where hybridization and isolation lead to rapid changes in beak size and shape. In fact, this phenomenon is so prevalent that it has its own name in the literature—contemporary evolution.
Darwin himself noted that domestic breeds (like dogs or pigeons) show more diversity than wild species. If humans can produce hundreds of dog breeds in a few thousand years by isolating traits, natural processes acting on created diversity could easily produce the wild species we see (like zebras, horses, and donkeys) from a single created kind in a similar timeframe.
Molecular Clocks
Finally, when we look at Mitochondrial DNA (mtDNA)—which is passed down only from mothers—we find a “clock” that fits the biblical timeline perfectly.
The number of mtDNA differences between modern humans fits a timescale of about 6,000 years, not hundreds of thousands. While mtDNA clocks suggest a recent mutation accumulation, nuclear DNA differences are too numerous to be explained by mutation alone in 6,000 years. This confirms that the nuclear diversity must be frontloaded (original variety), while the mtDNA diversity represents mutational history.
Conclusion
The Created Heterozygosity model explains the origin of species by recognizing that God engineered life with the capacity to adapt, diversify, and fill the earth. It accounts for the massive genetic variation we see today without ignoring the mathematical impossibility of evolving that information from scratch. Rather than being a reaction against science, this model embraces modern genetic data—from the limits of natural selection to the reality of genetic entropy—to provide a robust history of life.
Part VII: Created Heterozygosity & Natural Processes
The evidence for Created Heterozygosity, specifically within the Created Heterozygosity & Natural Processes (CHNP) model, makes several important predictions that distinguish it from the standard Darwinian explanations.
Prediction 1: “Major” Allelic Architecture
If the created heterozygosity is correct, each gene locus of the human line should feature no more than four predominant alleles encoding functional, distinct proteins. This is a prediction based on Adam and Eve having a total of four genome copies altogether. This prediction can be refined, however, to be even more particular.
Based on an analysis of the ABO gene within the Created Heterozygosity and Natural Processes (CHNP) model, the evidence suggests there were only two major alleles in the original created pair (Adam and Eve), rather than the theoretical maximum of four, for the following reasons:
1. Only A and B are Functionally Distinct “Major” Alleles
While a single pair of humans could theoretically carry up to four distinct alleles (two per person), the molecular data for the ABO locus reveals only two distinct, functional genetic architectures: A and B. The A and B alleles code for functional glycosyltransferase enzymes. They differ from each other by only seven nucleotides, four of which result in amino acid changes that alter the enzyme’s specificity. In an analysis of 19 key human functional loci, ABO is identified as having “dual majors.” These are the foundational, optimized alleles that are highly conserved and predate human diversification. Because A and B represent the only two functional “primordial” archetypes, the CHNP model posits that the original ancestors possessed the optimal A/B heterozygous genotype.
2. The ‘O’ Allele is a Broken ‘A.’
The reason there are not three (or four) original alleles (e.g., A, B, and O) is that the O allele is not a distinct, original design. It is a degraded version of the A allele.
The most common O allele (O01) is identical to the A allele except for a single guanine deletion at position 261. This deletion causes a frameshift mutation, resulting in a truncated, non-functional enzyme. Because the O allele is simply a broken A allele, it represents a loss of information (genetic entropy) rather than originally created diversity. The CHNP model predicts that initial kinds were highly functional and optimized, containing no non-functional or suboptimal gene variants. Therefore, the non-functional O allele would not have been present in the created pair but arose later through mutation.
3. AB is Optimal For Both Parents
A critical medical argument for the AB genotype in both parents (and therefore 2 Major created alleles) concerns the immune system and pregnancy. The CHNP model suggests that an optimized creation would minimize physiological incompatibility between the first mother and her offspring.
In the ABO system, individuals naturally produce antibodies against the antigens they lack. A person with Type ‘A’ blood produces anti-B antibodies; a person with Type ‘B’ produces anti-A antibodies; and a person with Type O produces both.
Individuals with Type AB blood produce neither anti-A nor anti-B antibodies because they possess both antigens on their own cells.
If the original mother (Eve) were Type A, she would carry anti-B antibodies, which could potentially attack a Type B or AB fetus (Hemolytic Disease of the Newborn). However, if she were Type AB, her immune system would tolerate fetuses of any blood type (A, B, or AB) because she lacks the antibodies that would attack them.
If there were more than two original antigens, these problems would be inevitable. The only solution is for both parents to share the same two antigens.
4. Disclaimer about scope
This, along with many other examples within the gene catalogue, suggests most, if not all, original gene loci were bi-allelic for homozygosity. This is not to say all were, as we do not have definitive proof of that, and there are several, e.g., immuno-response genes, loci which could theoretically have more than two Majors. However, it is highly likely that all genetic diversity can be explained by bi-genome, and not quad-genome, diversity. Greater modern diversity, if present, can consistently be partitioned into two functional clades, with subsidiary alleles emerging via SNPs, InDels, or recombinations over short timescales.
Prediction 2: Cross-Species Conservation
Having similar genes is essential in a created world in order for ecosystems to exist; it shouldn’t be surprising that we share DNA with other organisms. From that premise, it follows that some organisms will be more or less similar, and those can be categorized. Due to the laws of physics and chemistry, there are inherent design constraints on forms of biota. Due to this, it is expected that there will be functional genes that are shared throughout life where they are applicable. For instance, we share homeobox genes with much of terrestrial life, even down to snakes, mice, flies, and worms. These genes are similar because they have similar functions. This is precisely what we would predict from a design hypothesis.
Both models (CHNP and EES) predict that there will be some shared functional operations throughout all life. Although this prediction does lean more in favor of a design hypothesis, it is roughly agnostic evidence. However, what is a differentiating prediction is that “major” alleles will persist across genera, reflecting shared functional design principles, whereas non-functional variants will be species-specific. This prediction is due to the two models ’ different understandings of the power of evolutionary processes to explain diversity.
This prediction can be tested (along with the first) by examining allelic diversity (particularly in sequence alignment) across related and non-related populations. For instance, take the ABO blood type gene again. The genetic data confirm that functional “major” alleles are conserved across species boundaries, while non-functional variants are species-specific and recent.
1. Major Alleles (A and B): Shared Functional Design
Both models acknowledge that the functional A and B alleles are shared between humans and other primates (and even some distinct mammals). However, the interpretation differs, and the CHNP model posits this as evidence of major allelic architecture—original, front-loaded functional templates.
The functional A and B alleles code for specific glycosyltransferase enzymes. Sequence analysis shows that humans, chimpanzees, and bonobos share the exact same genetic basis for these polymorphisms. This fits the prediction that “major” alleles represent the optimized, original design. Because these alleles are functional, they are conserved across genera (trans-species), reflecting a common design blueprint rather than convergent evolution or deep-time descent.
Standard evolution attributes this to “trans-species polymorphism,” arguing that these alleles have been maintained by “balancing selection” for 20 million years, predating the divergence of humans and apes.
2. Non-Functional Alleles (Type O): The Differentiating Test
The crucial test arises when examining the non-functional ‘O’ allele. Because the ‘O’ allele confers a survival advantage against severe malaria, the standard evolutionary model must do one of the following: 1) explain why it is not the case that A and B, the ‘O’ alleles are not all three ancient and shared across lineages (trans-species inheritance), or provide an example of a shared ‘O’ allele across a kind-boundary. The reason why this prediction must follow is that the ‘O’ allele, being the null version, by evolutionary definition must have existed prior to either ‘A’ or ‘B’. What’s more, ‘A’ and ‘B’ alleles can easily break and the ‘O’ is not significant enough to be selected out of a given population.
In humans, the most common ‘O’ allele (O01) results from a specific single nucleotide deletion (a guanine deletion at position 261), causing a frameshift that breaks the enzyme. However, sequence analysis of chimpanzees and other primates reveals that their ‘O’ alleles result from different, independent mutations.
Human and non-human primate ‘O’ alleles are species-specific and result from independent silencing mutations. The mutation that makes a chimp Type ‘O’ is not the same mutation that makes a human Type ‘O’.
This supports the CHNP prediction that non-functional variants arise after the functional variants from recent genetic entropy (decay) rather than ancient ancestry. The ‘O’ allele is not a third “created” allele; it is a broken ‘A’ allele that occurred independently in humans and chimps after they were distinct populations. It has become fixated in populations, such as those native to the Americas, due to the beneficial nature of the gene break.
This brings us, also, back to the evolutionary problems we mentioned. Even if these four or more beneficial mutations could occur to create one ‘A’ or ‘B’ allele, which we discussed as being incredibly unlikely, either gene would break likely at a faster rate (due to Muller’s Ratchet) than could account for the fixity of A and B in primates and other mammals.
3. Timeline and Entropy
The mutational pathways for the human ‘O’ allele fit a timeline of <10,000 years, appearing after the initial “major” alleles were established. This aligns with the CHNP view that variants arise via minimal genetic changes (SNPs, Indels) within the last 6,000–10,000 years.
The emergence of the ‘O’ allele is an example of cis-evolution (diversification within a kind via information loss). It involves breaking a functional gene to gain a temporary survival advantage (malaria resistance), which is distinct from the creation of new biological information.
4. Broader Loci Analysis
This pattern is not unique to ABO. An analysis of 19 key human functional loci (including genes for immunity, metabolism, and pigmentation) confirms the “Major Allele” prediction:
Out of the 19 loci, 16 exhibit a single (or dual, like ABO) major functional allele that is highly conserved across species. Meaning that the functional versions of the genes are shared with other primates, mammals, vertebrates, or even eukaryotes. In contrast, non-functional or pathogenic variants (such as the CCR5-Δ32 deletion or CFTR mutations) are predominantly human-specific and arose recently (often <10,000 years ago). And when similar non-functional traits appear in different species (e.g., MC1R-loss, or ‘O’ blood group), they are due to convergent, independent mutations, not shared ancestry.
To illustrate this point, below is a graph from the paper testing the CHNP model in 19 functional genes. Table 1 summarizes key metrics for each locus. Across the dataset, 84% (16/19) exhibit a single major functional allele conserved >90% across mammals/primates, with variants emerging <50,000 years ago (kya). ABO and HLA-DRB1 align with dual ancient clades; SLC6A4 shows neutral biallelic drift. Non-functional variants (e.g., nulls, deficiencies) are human-specific in 89% of cases, often via single SNPs/InDels.
Locus
Major Allele(s)
Functional Groups (Ancient?)
Cross-Species Conservation
Variant Derivation (Changes/Time)
Model Fit (1/2/3)
HLA-DRB1
Multiple lineages (e.g., *03, *04)
2+ ancient clades (pre-Homo-Pan)
High in primates (trans-species)
Recombinations/SNPs; post-speciation (~100 kya)
Strong (clades); Partial (multi); Strong
ABO
A/B (O derived)
2 ancient (A/B trans-species)
High in primates
Inactivation (1 nt del.); <20 kya
Strong; Strong; Strong
LCT
Ancestral non-persistent (C/C)
1 major
High across mammals
SNPs (e.g., -13910T); ~10 kya
Strong; Strong; Strong
CFTR
Wild-type (non-ΔF508)
1 major
High across vertebrates
3 nt del. (ΔF508); ~50 kya
Strong; Strong; Strong
G6PD
Wild-type (A+)
1 major
High (>95% identity)
SNPs at conserved sites; <10 kya
Strong; Strong; Strong
APOE
ε4 (ancestral)
1 major (ε3/2 derived)
High across mammals
SNPs (Arg158Cys); <200 kya
Strong; Strong; Partial
CYP2D6
*1 (wild-type)
1 major
Moderate in primates
Deletions/duplications; recent
Strong; Partial; Strong
FUT2
Functional secretor
1 major
High in vertebrates
Truncating SNPs; ancient nulls (~100 kya)
Strong; Strong; Partial
HBB
Wild-type (HbA)
1 major
High across vertebrates
SNPs (e.g., sickle Glu6Val); <10 kya
Strong; Strong; Strong
CCR5
Wild-type
1 major
High in primates
32-bp del.; ~700 ya
Strong; Strong; Strong
SLC24A5
Ancestral Ala111 (dark skin)
1 major
High across vertebrates
Thr111 SNP; ~20–30 kya
Strong; Strong; Strong
MC1R
Wild-type (eumelanin)
1 major
High across mammals
Loss-of-function SNPs; convergent in some
Strong; Partial (conv.); Strong
ALDH2
Glu504 (active)
1 major
High across eukaryotes
Lys504 SNP; ~2–5 kya
Strong; Strong; Strong
HERC2/OCA2
Ancestral (brown eyes)
1 major
High across mammals
rs12913832 SNP; ~10 kya
Strong; Strong; Strong
SERPINA1
M allele (wild-type)
1 major
High in mammals (family expansion)
SNPs (e.g., PiZ Glu342Lys); recent
Strong; Strong; Strong
BRCA1
Wild-type
1 major
High in primates
Frameshifts/nonsense; <50 kya
Strong; Strong; Strong
SLC6A4
Long/short 5-HTTLPR
2 neutrally evolved
High across animals
InDel (VNTR); ancient (~500 kya)
Partial; Strong; Partial
PCSK9
Wild-type
1 major
High in primates (lost in some mammals)
SNPs (e.g., Arg469Trp); recent
Strong; Strong (conv. loss); Strong
EDAR
Val370 (ancestral)
1 major
High across vertebrates
Ala370 SNP; ~30 kya
Strong; Strong; Strong
Table 1: Evolutionary Profiles of Analyzed Loci. Model Fit: Tenet 1 (major architecture), 2 (conservation), 3 (derivation). “Partial” indicates minor deviations (e.g., multi-clades or potentially >10 kya).
This is devastating for modern synthesis. If the pattern that arises is one of shared functions and not shared mistakes, the theory is dead on arrival.
Prediction 3: Derivation Dynamics
Another important prediction to consider is due to the timeline for creating heterozygosity. If life were designed young (an entailment for CHNP), variant alleles must have arisen from “majors” through minimal modifications, feasible within roughly 6 to 10 thousand years.
To look at the ABO blood group once more, we see the total feasibility of this prediction. The ABO blood group, again, offers a “cornerstone” example, demonstrating how complex diversity collapses into simple, recent mutational events.
1. The ABO Case Study: Minimal Modification
The CHNP model identifies the A and B alleles as the original, front-loaded “major” alleles created in the founding pair. The diversity we see today (such as the various O alleles and A subtypes) supports the prediction of minimal, recent modification:
As we’ve discussed, the most common O allele (O01) is not a novel invention; it is a broken ‘A’ allele. It differs from the ‘A’ allele by a single guanine deletion at position 261. This minute change causes a frameshift that renders the enzyme non-functional. Other ABO variants show similar minimal changes. The A2 allele (a weak version of A) results from a single nucleotide deletion and a point mutation. The B3 allele results from point mutations that reduce enzymatic activity.
These are not complex architectural changes requiring millions of years. They are “typos” in the code. Molecular analysis confirms that the mutation causing the O phenotype is a common, high-probability event.
2. The Mathematical Feasibility of the Timeline
A mathematical breakdown can be used to demonstrate that these variants would inevitably arise within a young-earth timeframe using standard mutation rates.
Using a standard mutation rate (1.5×10^−8 per base pair per generation) and an exponentially growing population (starting from founders), mutations accumulate rapidly and easily. Calculations suggest that in a population growing from a small founder group, the first expected mutations in the ABO exons would appear as early as Generation 4 (approx. 80 years). Over a period of 5,000 years, with a realistic population growth model, the 1,065 base pairs of the ABO exons would theoretically experience tens of thousands of mutation events. The gene would be thoroughly saturated, meaning virtually every possible single-nucleotide change would have occurred multiple times.
Specific estimates for the emergence of the ‘O’ allele place it within 50 to 500 generations (1,000 to 10,000 years) under neutral drift, or even faster with selective pressure. This perfectly fits the CHNP timeline of 6,000-10,000 years.
3. Further Validation: The 19 Loci Analysis
This pattern of “Ancient Majors, Recent Variants” is not unique to ABO. The 19 key human functional loci study also confirms that this is a systemic feature of the human genome.
Across genes involved in immunity, metabolism, and pigmentation, derived variants consistently appear to have arisen within the last 10,000 years (Holocene). ALDH2: The variant causing the “Asian flush” (Glu504Lys) is estimated to be ~2,000 to 5,000 years old. LCT (Lactase Persistence): The mutation allowing adults to digest milk arose ~10,000 years ago, coinciding with the advent of dairy farming. HBB (Sickle Cell): The hemoglobin variant conferring malaria resistance emerged <10,000 years ago. In 89% of the analyzed cases, these variants are caused by single SNPs or Indels derived from the conserved major allele.
The prediction that variant alleles must be derived via minimal modifications feasible within a young timeframe is strongly supported by the genetic data. The ABO system demonstrates that the “O” allele is merely a single deletion that could arise in less than 100 generations.
This confirms the CHNP view that while the “major” alleles (A and B) represent the original, complex design (Major Allelic Architecture), the variants (O, A2, etc.) are the result of recent, rapid genetic entropy (cis-evolution) that requires no deep-time evolutionary mechanisms to explain.
An ABO Blood Group Paradox
As we have run through these first three predictions of the Created Heterozygosity model, we have dealt particularly with the ABO gene and have run into a peculiar evolutionary puzzle. Let’s first speak of this paradox more abstractly in the form of an analogy:
Imagine a family of collectors who passed down two distinct types of antique coins (Coins A and B) to their descendants over centuries because those coins were valuable. If a third type of coin (Coin O) was also extremely valuable (offering protection/advantage) and easier to mint, you would predict the Ancestors would have kept Coin O and passed it down to both lineages alongside A and B. You wouldn’t expect the descendants to inherit A and B from the ancestor, but have to invent Coin O continuously from scratch every generation.
By virtue of this same logic, evolutionary models must predict that the ‘O’ allele should be ancient (20 million years) due to balancing selection. However, the genetic data shows ‘O’ alleles are recent and arose independently in different lineages. This supports the CHNP view: the original ancestors were created with functional A and B alleles (heterozygous), and the O allele is a recent mutational loss of function.
Prediction 4: Rapid Speciation and Adaptive Radiation
If created heterozygosity is true, and organisms were designed with built-in potential for adaptation given their environment, then we should expect to find mechanisms of extreme foresight that permit rapid change to external stressors. There are, in fact, many such mechanisms which are written about in the scientific literature: contemporary evolution, natural genetic engineering, epigenetics, higher agency, continuous environmental tracking, non-random evolution, evo-devo, etc.
The phenomenon of adaptive radiation—where a single lineage rapidly diversifies into many species—is clearly differentiating evidence for front-loaded heterozygosity rather than mutational evolution. Why? Because random mutation has no foresight. Random mutations do not prepare an organism for any eventuality. If it is not useful now, get rid of it. That is the mantra of evolutionary theory. That is the premise of natural selection. However, this premise is drastically mistaken.
The foundation of this alternative view is that genetic change is not accidental. Molecular biologist James Shapiro argues that cells are not passive victims of random “copying errors.” Instead, they possess “active biological functions” to restructure their own genomes. Cells can cut, splice, and rearrange DNA, often using mobile genetic elements (transposons) and retroviruses to rewrite their genetic code in response to stress. Shapiro calls the genome a “read-write” database rather than a read-only ROM.
Building on this, Dr. Lee Spetner proposed that organisms have a built-in capacity to adapt to environmental triggers. These changes are not rare or accidental but can occur in a large fraction of the population simultaneously. This work is supported by modern research from people like Dr. Michael Levin and Dr. Dennis Noble. Mutations are revealing themselves to be more and more a predictable response to environmental inputs.
2. The Architecture: Continuous Environmental Tracking (CET)
If organisms engineer their own genetics, how do they know when to do it? This is where CET provides the engineering framework.
Proposed by Dr. Randy Guliuzza, CET treats organisms as engineered entities. Just like a self-driving car, organisms possess input sensors (to detect the environment), internal logic/programming (to process data), and output actuators (to execute biological changes). In Darwinism, the environment is the “selector” (a sieve). In CET, the organism is the active agent. The environment is merely the data the organism tracks. For example, blind cavefish lose their eyes not because of random mutations and slow selection, but because they sense the dark environment and downregulate eye development to conserve energy, a process that is rapid and reversible. More precisely, the regulatory system of these cave fish specimens can detect the low salinity of cave water, which triggers the effect of blindness over a short timeframe.
3. The Software: Epigenetics
Epigenetics acts as the “formatting” or the switches for the DNA computer program. Epigenetic mechanisms (like methylation) regulate gene expression without changing the underlying DNA sequence. This allows organisms to adapt quickly to environmental cues—such as plants changing flowering times or root structures. These changes can be heritable. For instance, the environment of a parent (e.g., diet, stress) can affect the development of the offspring via RNA absorbed by sperm or eggs, bypassing standard natural selection. This blurs the line between the organism and its environment, facilitating rapid adaptation.
4. The Result: Contemporary Evolution
When these internal mechanisms (NGE, CET, Epigenetics) function, the result is Contemporary Evolution—observable changes happening in years or decades, not millions of years. Conservationists and biologists are observing “rapid adaptation” in real-time. Examples include invasive species changing growth rates in under 10 years, or the rapid diversification of cichlid fish in Lake Victoria.
For Young Earth Creationists (YEC), Contemporary Evolution validates the concept of Rapid Post-Flood Speciation. It shows that getting from the “kinds” on Noah’s Ark to modern species diversity in a few thousand years is biologically feasible.
Conclusion
So, where does the information for all this diversity come from? This is the specific model (CHNP) that explains the source of the variation being tracked and engineered.
This model posits that original kinds were created as pan-heterozygous (carrying different alleles at almost every gene locus). As populations grew and migrated (Contemporary Evolution), they split into isolated groups. Through sexual reproduction (recombination), the original heterozygous traits were shuffled. Over time, specific traits became “fixed” (homozygous), leading to new species.
This model argues that random mutation cannot bridge the gap between distinct biological forms (the Valley of Death) due to toxicity and complexity. Therefore, diversity must be the result of sorting pre-existing (front-loaded) functional alleles rather than creating new ones from scratch.
Look at it this way:
1. Mendelian Speciation/Created Heterozygosity is the Resource: It provides the massive library of latent genetic potential (front-loaded alleles).
2. Continuous Environmental Tracking is the Control System: It uses sensors and logic to determine which parts of that library are needed for the current environment.
3. Epigenetics and Natural Genetic Engineering are the Mechanisms: They are the tools the cells use to turn genes on/off (epigenetics) or restructure the genome (NGE) to express those latent traits.
4. Contemporary Evolution is the Observation: It is the visible, rapid diversification (cis-evolution) we see in nature today as a result of these internal systems working on the front-loaded information.
Together, these concepts argue that organisms are not passive lumps of clay shaped by external forces (Natural Selection), but sophisticated, engineered systems designed to adapt and diversify rapidly within their kinds.
The mechanism driving this diversity is the recombination of pre-existing heterozygous genes. Just 20 heterozygous genes can theoretically produce over one million unique homozygous phenotypes. As populations isolate and speciate, they lose their initial heterozygosity and become “fixed” in specific traits. This process, known as cis-evolution, explains diversity within a kind (e.g., wolves to dog breeds) but differs fundamentally from trans-evolution (evolution between kinds), which finds no mechanism in genetics.
The CHNP model argues that mutations are insufficient to create the original genetic information due to thermodynamic and biological constraints. De novo protein creation is hindered by a “Valley of Death”—a region of sequence space where intermediate, misfolded proteins are toxic to the cell. Natural selection eliminates these intermediates, preventing the gradual evolution of novel protein folds.
Mechanisms often cited as creative, such as gene duplication or recombination, are actually “remixing engines.” Duplication provides redundancy, not novelty, and recombination shuffles existing alleles without creating new genetic material. Because mutations are modifications (typos) rather than creations, the original functional complexity must have been present at the beginning.
Genetics reveals that organisms contain “latent” or hidden information that can be expressed later.
Information can be masked by dominant alleles or epistatic interactions (where one gene suppresses another). This allows phenotypic traits to remain hidden for generations and reappear suddenly when genetic combinations shift, facilitating rapid adaptation without new mutations.
Genetic elements like transposons can reversibly activate or deactivate genes (e.g., in grape color or peppered moths), acting as switches for pre-existing varieties rather than creators of new genes.
Summary
The genetic evidence for created heterozygosity rests on the observation that biological novelty is ancient and conserved, while variation is recent and degenerative. By starting with ancestors endowed with high levels of heterozygosity, the “forest” of life’s diversity can be explained by the rapid sorting and recombination of distinct, front-loaded genetic programs.
In his paper “Life Transcending Physics and Chemistry,” Michael Polanyi examines biological machines in a way that illuminates the explanatory failures of materialism. The prevailing materialist paradigm that life can be fully explained by the laws of inanimate nature fails to account for higher ordered realities which have operations and structures that involve non-material judgements and interpretations. He specifically addresses the views of scientists such as Francis Crick, who, along with James Watson, argued for a total reductionist and nominalist view based on their discovery of DNA. For Polanyi, there is a life-transcending nature that all biological organisms have which is akin to machines and their transcendent properties. His central argument is based on the concept of “boundary control,” which argues the notion that there are laws that govern physical reactions (as Crick would accept) yet there are particular laws of form and function which are unique and separate from those lower-level laws.
There is a real clash between Polanyi’s position and the reductionist/nominalist position which is commonly held by molecular biologists. To start to broach this divergence he explains how the contemporaneous discovery of the genetic function of DNA was interpreted as the final blow to vitalist thought within sciences. He writes:
“The discovery by Watson and Crick of the genetic function of DNA (deoxyribonucleic acid), combined with the evidence these scientists provided for the self-duplication of DNA, is widely held to prove that living beings can be interpreted, at least in principles, by the laws of physics and chemistry.”
Polanyi explicitly rejects Crick’s interpretation; that position is of the mainstream and popular level academia. Crick states that his principle “has so far been accepted by few biologists and has been sharply rejected by Francis Crick, who is convinced that all life can be ultimately accounted for by the laws of inanimate nature.” This same sentiment can indeed be found in Crick’s book “Molecules and Man.” Crick writes the following:
“Thus eventually one may hope to have the whole of biology “explained” in terms of the level below it, and so on right down to the atomic level.”
To dismantle the materialist argument, Polanyi utilizes the analogy of a machine. A machine cannot be defined or understood solely through the physical and chemical properties of its materials. Take a watch and put it into a machine that can read a detailed atomic map of the device: can even the best chemist give any coherent reason as to whether the watch is functioning or not? Worse—can one even tell you what a watch is, if all that exists is matter in motion for no particular reason? Polanyi writes it best:
“A complete physical-chemical topography of my watch—even though the topography included the changes caused by the movements in the watch—would not tell us what this object is. On the other hand, if we know watches, we would recognize an object as a watch by a description of it which says that it tells the time of the day… We know watches and can describe one only in terms like ‘telling the time,’ ‘hands,’ ‘face,’ ‘marked,’ which are all incapable of being expressed by the variables of physics, length, mass, and time.”
Once you see this distinction, you are invariably led (as Polanyi was) to two unique substratum of explanation; what he calls the concept of dual control. Obviously, there are physical laws which dictate constraints and operations of all material and all material things can be explained by these very laws. However, those laws are only meaningfully called constraints when there is some notion of intention or design to be constrained. The shape of any machine, man-made or biological, is not determined by natural laws. Not only is it not determined by them, it cannot be determined by them in any way. Polanyi elaborates on this relationship:
“The machine is a machine by having been built and being then controlled according to principles of engineering. The laws of physics and chemistry are indifferent to these principles; they would go on working in the fragments of the machine if it were smashed. But they serve the machine while it lasts; machines rely for their operations always on the laws of physics and chemistry.”
As I hinted at before, Polanyi also applies this logic to biological systems, arguing that morphology is a boundary condition in the same way that a design of a machine is a boundary condition. Biology cannot be reduced to physics because the structure that defines a living being is not the result of physical-chemical equilibration. Physical laws do not intend to create nor do they care that anything functions. Instead, “biological principles are seen then to control the boundary conditions within which the forces of physics and chemistry carry on the business of life.”
Where Polanyi and Crick truly have the disagreement, then, is in their interpretation of the explanatory power of nature and how DNA is implicated within these frameworks. While Crick views DNA as a chemical agent that proves reducibility, Polanyi argues that the very nature of DNA as an information carrier proves the opposite. For a molecule to function as a code, its sequence cannot be determined by chemical necessity. If chemical laws dictated the arrangement of the DNA molecule, it would be a rigid crystal incapable of conveying complex, variable information. Polanyi writes:
“Thus in an ideal code, all alternative sequences being equally probable, its sequence is unaffected by chemical laws, and is an arithmetical or geometrical design, not explicable in chemical terms.”
By treating DNA as a transmitter of information, Polanyi aligns it with other non-physical forms of communication, such as a book. The physical chemistry of the ink and paper does not explain the content of the text. Similarly, the chemical properties of DNA do not explain the genetic information it carries. Polanyi contends that Crick’s own theory inadvertently supports this non-materialist conclusion:
“The theory of Crick and Watson, that four alternative substituents lining a DNA chain convey an amount of information approximating that of the total number of such possible configurations, amounts to saying that the particular alignment present in a DNA molecule is not determined by chemical forces.”
Therefore, the pattern of the organism, derived from the information in DNA, represents a constraint that physics cannot explain. It is a boundary condition that harnesses matter. Polanyi concludes that the organization of life is a specific, highly improbable configuration that transcends the laws governing its atomic constituents:
“When this structure reappears in an organism, it is a configuration of particles that typifies a living being and serves its functions; at the same time, this configuration is a member of a large group of equally probable (and mostly meaningless) configurations. Such a highly improbable arrangement of particles is not shaped by the forces of physics or chemistry. It constitutes a boundary condition, which as such transcends the laws of physics and chemistry.”
In this way, Polanyi refutes the nominalist materialist perspective by demonstrating that the governing principles of life—its form, function, and information content—are logically distinct from, and irreducible to, the physical laws that govern inanimate matter. Physical laws are, then, merely a piece of the puzzle of the explanation. What’s more, they are insufficient to account for the existence of particular organizations of matter which physical laws and chemistry are not determinative of.
For a creationist, it’s clear as day why. There are two equivocal definitions being used which blur the lines and convolute any attempt at productive dialogue.
“Change in allele frequencies in a population over time.”
The breakdown: Alleles represent versions of genes in which a part of the gene is different, which often makes the overall functional outcome in some way different.
The frequencies in a population are the ratio of members with or without an allele.
Finally, the premise of this definition is that the number of organisms in a population with a certain trait can grow or diminish over time.
This seems to me a very uncontroversial thing to hold to. Insofar as evolution could be a fact, this is certainly hard to deny.
All that is needed for this first definition is mechanisms for sorting and redistribution of existing variation.
However, what is commonly inferred from the term is an altogether separate conception:
“All living things are descended from a common ancestor.”
This is clearly different. An evolutionist may agree, but argue that these are merely differences in degree (or scale). But is that the case?
The only way to know whether the one definition flows seamlessly into the next or whether this is a true equivocation is to understand the underlying mechanism. For instance, let’s talk about movement.
South America and Asia are roughly four times further apart than Australia and Antarctica. Yet, I could say, rightly, that I could walk from South America to Asia, but I could not say the same about Australia and Antarctica. Why is this? If I can walk four times the distance in one instance, why should I be thus restricted?
The obvious reason is this: Australia and Antarctica are separated by the entire width of the deep, open Southern Ocean and the Tasman Sea. I should not expect that I can traverse, by walking, two places with no land betwixt them.
The takeaway is this: My extrapolation is only good so long as my mechanism is sufficient. Walking is only possible with land bridges. Without land bridges, it doesn’t matter the distance; you’re not going to make it.
This second definition requires mechanisms for sorting and redistribution of existing variation as well as creation of new biological information and structures.
With that consideration, let us now take this lesson and apply it to the mechanisms of change which evolutionists espouse.
There are many, but we will quickly narrow our search.
Natural Selection: This is any process that acts as a culling from the environment (which can be ecology, climate, niche, etc).
Gene Flow: This is the reproductive isolation of populations.
Genetic Drift/Draft: This is any process that causes fluctuations in alleles due to a lack of selection pressures.
Sexual Selection/Non-Random Mating: This is the process by which organisms preferentially choose phenotypes.
The point of this exercise is to observe that these are all mechanisms of sorting and redistribution of existing variation, but they are not the mechanisms that create that variation in the first place. Any mechanism that lacks creative power is insufficient to account for our second definition.
The mechanism that is left is, you might have guessed, mutation.
Here’s the problem: mutation is its own conflation. We need to unravel the many ways in which DNA can change. There are many kinds of mutations, and what’s true for one may not be true for another. For example, it is often said that mutations are:
Copying errors
Creative
Random with respect to fitness
However, this is hardly the case for many various types of phenomena that are classified as mutations.
For instance, take recombination.
Recombination is nota copy error. It is a very particular and facilitated meiotic process that requires deliberate attention and agency.
Recombination is notcreative. Although it can technically cause a change in allele frequencies (as a new genotype is being created), so can every other non-creative process. It can no more create new genetic material than a card shuffler can create new cards.
Recombination is not random with respect to fitness. Even with recombination, like a card shuffler, being random in one sense, there is a telos about particular random processes that make them constitute something not altogether random. If we take a card shuffler, it is not random with respect to the “fitness” of the card game. In fact, it is specifically designed to make a fairer and balanced game night. Likewise, recombination, particularly homologous recombination (HR), is fundamentally a high-fidelity DNA repair pathway. It is designed to prevent the uninterrupted spread of broken or worse genes within a single genotype. Like the card shuffler, the mechanism of recombination has no foresight, but it has an explicit function nonetheless.
Besides recombination, there are many discrete ways in which mutations can happen. On the small scale, we see things like Single Nucleotide Polymorphisms (SNPs) and Insertions and Deletions (Indels). Zooming out, we also find mutations such as duplications & deletions of genes or multiple genes (e.g., CNVs), exon shuffling, and transposable elements. On the grand scale, we see events such as whole genome duplications and epigenetic modifications as well.
On the small scale, Single Nucleotide Polymorphisms (SNPs) and Insertions and Deletions (Indels) are the equivalent of typos or missing characters within an existing blueprint. While a typo can certainly change the meaning of a sentence, it cannot generate a completely new architectural plan. It modifies the existing instruction set; it does not introduce a novel concept or function absent in the original text. These are powerful modifiers, but their action is always upon pre-existing information.
It is also the case that these mutations can never rightly be called evolution. They are not creative; they are only destructive mechanisms. Copy errors create noise, not clarity, in information systems.
Further, these small-scale mutations happen within the context of the preexisting structure and integrity of the genome. So that, even those which are said to be beneficial are preordained to be so by some higher design principles. For instance, much work has been done to show that nucleosomes protect DNA from damage and structural variants stabilize regions where they emerge:
“Structural variants (SVs) tend to stabilize regions in which they emerge, with the effect most pronounced for pathogenic SVs. In contrast, the effects of chromothripsis are seen across regions less prone to breakages. We find that viral integration may bring genome fragility, particularly for cancer-associated viruses.” (Pflughaupt et al.)
“Eukaryotic DNA is organized in nucleosomes, which package DNA and regulate its accessibility to transcription, replication, recombination, and repair… living cells nucleosomes protect DNA from high-energy radiation and reactive oxygen species.” (Brambilla et al.)
Moving to the medium scale, consider duplications and deletions (CNVs) and exon shuffling. Gene duplication, often cited as a source of novelty, is simply copying an entire, functional module—a paragraph or even a full chapter. This provides redundancy. It is often supposed that this allows one copy to drift while the original performs its necessary task. But gene duplications are not simply ignored by the genome or selective processes. They are often immediately discarded if they don’t infer a use, or otherwise, they are incorporated in a certain way.
“Gene family members may have common non-random patterns of origin that recur independently in different evolutionary lineages (such as monocots and dicots, studied here), and that such patterns may result from specific biological functions and evolutionary needs.” (Wang et al.)
Here we see that there is often a causal link between the needs of the organism and the duplication event itself. Further, we observe a highly selective process of monitoring post-duplication:
“Recently, a nonrandom process of gene loss after these different polyploidy events has been postulated [12,31,38]. Maere et al. [12] have shown that gene decay rates following duplication differ considerably between different functional classes of genes, indicating that the fate of a duplicated gene largely depends on its function.” (Casneuf et al.)
Even if the function conferred was redundancy, redundancy is not creation; it is merely an insurance policy for existing information. Where, precisely, is the mechanism that takes that redundant copy and molds it into a fundamentally new structure or process—say, turning a light-sensing pigment gene into a clotting factor? What is the search space that will have to be traversed? Indels and SNPs are not sufficient to modify a duplication into something entirely novel. Novel genes require novel sequences for coding specific proteins and novel sequences for regulation. Duplication at best provides a scratch pad, which is highly sensitive to being tampered with.
Exon shuffling, similarly, is a process of reorganization, splicing together pre-existing functional protein domains. This is the biological equivalent of an editor cutting and pasting sentences from one section into another. The result can be a new combination, but every word and grammatical rule was already present. It is the sorting and redistribution of parts.
Further, exon shuffling is a highly regulated process that has been shown to be constrained by splice frame rules and mediated by TEs in introns.
“Exon shuffling follows certain splice frame rules. Introns can interrupt the reading frame of a gene by inserting a sequence between two consecutive codons (phase 0 introns), between the first and second nucleotide of a codon (phase 1 introns), or between the second and third nucleotide of a codon (phase 2 introns).” (Wikipedia Contributors)
This Wikipedia article gives you a taste for the precision and intense regulation, prerequisite and premeditated, in order to perform what are essentially surgical operations to create specialized proteins for cellular operation. One of the reasons it is such a delicate process is portrayed in this journal article:
“Successful shuffling requires that the domain in question is bordered by introns that are of the same phase, that is, that the domain is symmetrical in accordance with the phase-compatibility rules of exon shuffling (Patthy 1999b), because shuffling of asymmetrical exons/domains will result in a shift of the reading frame in the downstream exons of recipient genes.” (Kaessmann)
In the same way, transposable elements are constrained by the epigenetic and structural goings-on of the genome. Research shows that transposase recognizes DNA structure at insertion sites, and there are physical constraints caused by chromatin:
“We show that all four of these measures of DNA structure deviate significantly from random at P element insertion sites. Our results argue that the donor DNA and transposase complex performing P element integration may recognize a structural feature of the target DNA.” (Liao Gc et al.)
Finally, we look at the grand scale. Whole Genome Duplication (WGD) is the ultimate copy-paste—duplicating the entire instructional library. Again, this provides massive redundancy but offers zero novel genetic information. This is not creative in any meaningful sense, even at the largest scale.
As for epigenetic modifications, these are critical regulatory mechanisms that determine when and how existing genes are expressed. They are the rheostats and switches of the cell, changing the output and timing without ever altering the source code (the DNA sequence). They are regulatory, not informational creators.
The central issue remains: The second definition of evolution requires the creation of new organizational blueprints and entirely novel biological functions.
The mechanism of change relied upon—mutation—is, across all its various types, fundamentally a system of copying, modification, deletion, shuffling, or regulation of existing, functional genetic information. None of these phenomena, regardless of their scale, demonstrates the capacity to generate the required novel information (the “land bridge”) necessary to traverse the vast gap between one kind of organism and another. Again, they are really great mechanisms for change over time, but they are pitiable creative mechanisms.
Therefore, the argument that the two definitions of evolution are merely differences of scale falls apart. The extrapolation from observing a shift in coat color frequency (Definition 1) to positing a common ancestor for all life (Definition 2) is logically insufficient. It requires a creative mechanism that is qualitatively different from the mechanisms of sorting and modification we observe. Lacking that demonstrated, information-generating mechanism, we are left with two equivocal terms, where one is an undeniable fact of variation and the other is an unsupported inference of mechanism—a proposal to walk across the deep, open ocean with only the capacity to walk on land.
Works Cited
Brambilla, Francesca, et al. “Nucleosomes Effectively Shield DNA from Radiation Damage in Living Cells.” Nucleic Acids Research, vol. 48, no. 16, 10 July 2020, pp. 8993–9006, pmc.ncbi.nlm.nih.gov/articles/PMC7498322/, https://doi.org/10.1093/nar/gkaa613. Accessed 30 Oct. 2025.
Casneuf, Tineke, et al. “Nonrandom Divergence of Gene Expression Following Gene and Genome Duplications in the Flowering Plant Arabidopsis Thaliana.” Genome Biology, vol. 7, no. 2, 2006, p. R13, https://doi.org/10.1186/gb-2006-7-2-r13. Accessed 7 Sept. 2021.
Kaessmann, H. “Signatures of Domain Shuffling in the Human Genome.” Genome Research, vol. 12, no. 11, 1 Nov. 2002, pp. 1642–1650, https://doi.org/10.1101/gr.520702. Accessed 16 Jan. 2020.
Liao Gc, et al. “Insertion Site Preferences of the P Transposable Element in Drosophila Melanogaster.” Proceedings of the National Academy of Sciences of the United States of America, vol. 97, no. 7, 14 Mar. 2000, pp. 3347–3351, https://doi.org/10.1073/pnas.97.7.3347. Accessed 1 Dec. 2023.
Pflughaupt, Patrick, et al. “Towards the Genomic Sequence Code of DNA Fragility for Machine Learning.” Nucleic Acids Research, vol. 52, no. 21, 23 Oct. 2024, pp. 12798–12816, https://doi.org/10.1093/nar/gkae914. Accessed 8 Nov. 2025.
Wang, Yupeng, et al. “Modes of Gene Duplication Contribute Differently to Genetic Novelty and Redundancy, but Show Parallels across Divergent Angiosperms.” PLoS ONE, vol. 6, no. 12, 2 Dec. 2011, p. e28150, https://doi.org/10.1371/journal.pone.0028150. Accessed 20 Dec. 2021.
The evidence typically presented as definitive proof for the theory of common descent, the nested hierarchy of life and genetic/trait similarities, is fundamentally agnostic. This is because evolutionary theory, in its broad explanatory power, can be adapted to account for virtually any observed biological pattern post-hoc, thereby undermining the claim that these patterns represent unique or strong predictions of common descent over alternative models, such as common design.
I. The Problematic Nature of “Prediction” in Evolutionary Biology
Strict Definition of Scientific Prediction: A true scientific prediction involves foretelling a specific, unobserved phenomenon before its discovery. It is not merely explaining an existing observation or broadly expecting a general outcome.
Absence of Specific Molecular Predictions:
Prior to the molecular biology revolution (pre-1950s/1960s), no scientist explicitly predicted the specific molecular similarity of DNA sequences across diverse organisms, the precise double-helix structure, or the near-universal genetic code. These were empirical discoveries, not pre-existing predictions.
Evolutionary explanations for these molecular phenomena (e.g., the “frozen accident” hypothesis for the universal genetic code) were formulated after the observations were made, rendering them post-hoc explanations rather than predictive triumphs.
Interpreting broad conceptual statements from earlier evolutionary thinkers (like Darwin’s “one primordial form”) as specific molecular predictions is an act of “eisegesis”—reading meaning into the text—rather than drawing direct, testable predictions from it. A primordial form does not necessitate universal code, universal protein sequences, universal logic, or universal similarity.
II. The Agnosticism of the Nested Hierarchy
The Nested Hierarchy as an Abstract Pattern: The observation that life can be organized into a nested hierarchy (groups within groups, e.g., species within genera, genera within families) is an abstract pattern of classification. This pattern existed and was recognized (e.g., by Linnaeus) long before Darwin’s theory of common descent.
Compatibility with Common Design: A designer could, for various good reasons (e.g., efficiency, aesthetic coherence, reusability of components, comprehensibility), choose to create life forms that naturally fall into a nested hierarchical arrangement. Therefore, the mere existence of this abstract pattern does not uniquely or preferentially support common descent over a common design model.
Irrelevance of Molecular “Details” for this Specific Point: While specific molecular “details” (such as shared pseudogenes, endogenous retroviruses, or chromosomal fusions) are often cited as evidence for common descent, these are arguments about the mechanisms or specific content of the nested hierarchy. These are not agnostic and can be debated fruitfully. However, they do not negate the fundamental point that the abstract pattern of nestedness itself remains agnostic, as it could be produced by either common descent or common design.
III. Evolutionary Theory’s Excessive Explanatory Flexibility (Post-Hoc Rationalization)
Fallacy of Affirming the Consequent: The logical structure “If evolutionary theory (Y) is true, then observation (X) is expected” does not logically imply “If observation (X) is true, then evolutionary theory (Y) must be true,” especially if the theory is so flexible that it can explain almost any X.
Capacity to Account for Contradictory or Diverse Outcomes:
Genetic Similarity: Evolutionary theory could equally well account for a model with no significant genetic similarity between organisms (e.g., if different biochemical pathways or environmental solutions were randomly achieved, or if genetic signals blurred too quickly over time). For example, a world with extreme porportions of horizontal gene transfer (as seen in prokaryotic and rare eukaryotic cells)
Phylogenetic Branching: The theory is flexible enough to account for virtually any observed phylogenetic branching pattern. If, for instance, humans were found to be more genetically aligned with pigs than with chimpanzees, evolutionary theory would simply construct a different tree and provide a new narrative of common ancestry. This flexability puts a wedge in any measure of predictability claimed by the theory.
“Noise” in Data: If genetic data were truly “noise” (random and unpatterned), evolutionary theory could still rationalize this by asserting that “no creator would design that way, and randomness fully accounts for it,” thus always providing an explanation regardless of the pattern. In fact, a noise pattern is perhaps one of the few patterns better explained by random physical processes. Why would a designer, who has intentionality, create in such a slapdash way?
Convergence vs. Divergence: The theory’s ability to explain both convergent evolution (morphological similarity without close genetic relatedness) and divergent evolution (genetic differences leading to distinct forms) should imediately signal red-flags, as this is a telltale sign of a post-hoc fitting of observations rather than a result of specific prediction.
To illustrate this point, Let’s imagine we have seven distinct traits (A, B, C, D, E, F, G) and five hypothetical populations of creatures (P1-P5), each possessing a unique combination of these traits. For example, P1 has {A, B, C}, P2 has {A, D, E}, P3 has {A, F, G}, P4 has {B, D, F}, and P5 has {E, G}. When examining this distribution, we can construct a plausible “evolutionary story.” Trait ‘A’, present in P1, P2, and P3, could be identified as a broadly ancestral trait. P1 might be an early branch retaining traits B and C, while P2 and P3 diversified by gaining D/E and F/G respectively.
However, the pattern becomes more complex with populations like P4 and P5. P4’s mix of traits {B, D, F} suggests it shares B with P1, D with P2, and F with P3. An evolutionary narrative would then employ concepts like trait loss (e.g., B being lost in P2/P3/P5’s lineage), convergent evolution (e.g., F evolving independently in P4 and P3), or complex branching patterns. Similarly, P5’s {E, G} would be explained by inheriting E from P2 and G from P3, while also undergoing significant trait loss (A, B, C, D, F).
And this is the crux of the argument, given any observed distribution of traits, evolutionary theory’s flexible set of explanatory mechanisms—including common ancestry, trait gain, trait loss, and convergence—can always construct a coherent historical narrative. This ability to fit diverse patterns post-hoc renders the mere existence of a nested hierarchy, disconnected from specific underlying molecular details, as agnostic evidence for common descent over other models like common design.
IV. Challenges to Specific Evolutionary Explanations and Assumptions
Conservation of the Genetic Code:
The claim that the genetic code must remain highly conserved post-LUCA due to “catastrophic fitness consequences” of change is an unsubstantiated assumption. Granted, it could be true, but one can imagine plausible scenarios which could demonstrate exceptions.
Further, evolutionary theory already postulates radical changes, including the very emergence of complex systems “from scratch” during abiogenesis. If such fundamental transformations are possible, then the notion that a “new style of codon” is impossible over billions of years, even via incremental “patches and updates,” appears inconsistent.
Laboratory experiments that successfully engineer organisms to incorporate unnatural amino acids demonstrate the inherent malleability of the genetic code. Yet no experiment has demonstrate abiogenesis, a much more implausible event with less evolutionary time to play with. Why limit the permissible improbable things arbitrarily?
There is no inherent evolutionary reason to expect a single, highly conserved “language” for the genetic code; if information can be created through evolutionary processes, then multiple distinct solutions should be the rule.
Functionality of “Junk” DNA and Shared Imperfections:
The assertion that elements like pseudogenes and endogenous retroviruses (ERVs) are “non-functional” or “mistakes” is often an “argument from ignorance” or an “anti-God/atheism-of-the-gaps” fallacy. Much of the genome’s function is still unknown, and many supposedly “non-functional” elements are increasingly found to have regulatory or other biological roles. For instance, see my last article on the DDX11L2 “pseudo” gene which operates as a regulatory element including as a secondary promoter.
If these elements are functional, their homologous locations are easily explained by a common design model, where a designer reuses functional components across different creations.
The “functionality” of ERVs, for instance, is often downplayed in arguments for common descent, despite their known roles in embryonic development, antiviral defense, and regulation, thereby subtly shifting the goalposts of the argument.
Probabilities of Gene Duplication and Fusion:
The probability assigned to beneficial gene duplications and fusions (which are crucial for creating new genetic information and structures) seems inconsistently high when compared to the low probability assigned to the evolution of new codon styles. If random copying errors can create functional whole genes or fusions, then the “impossibility” of a new codon style seems a little arbitrary.
Conclusion:
The overarching argument is that while common descent can certainly explain the observed patterns in biology, its explanatory power often relies on post-hoc rationalization and a flexibility that allows it to account for almost any outcome. This diminishes the distinctiveness and predictive strength of the evidence, leaving it ultimately agnostic when compared to alternative models that can also account for the same observations through different underlying mechanisms.
The human genome contains numerous regulatory elements that control gene expression, including canonical and alternative promoters. While DDX11L2 is annotated as a pseudogene, its functional relevance in gene regulation has been a subject of interest. This study leverages publicly available genomic data from the UCSC Genome Browser, integrating information from the ENCODE project and ReMap database, to investigate the transcriptional activity within a specific intronic region of the DDX11L2 gene (chr2:113599028-113603778, hg38 assembly). Our analysis reveals the co-localization of key epigenetic marks, candidate cis-regulatory elements (cCREs), and RNA Polymerase II binding, providing robust evidence for an active alternative promoter within this region. These findings underscore the complex regulatory landscape of the human genome, even within annotated pseudogenes.
1. Introduction
Gene expression is a tightly regulated process essential for cellular function, development, and disease. A critical step in gene expression is transcription initiation, primarily mediated by RNA Polymerase II (Pol II) in eukaryotes. Transcription initiation typically occurs at promoter regions, which are DNA sequences located upstream of a gene’s coding sequence. However, a growing body of evidence indicates the widespread use of alternative promoters, which can initiate transcription from different genomic locations within or outside of a gene’s canonical promoter, leading to diverse transcript isoforms and complex regulatory patterns [1].
The DDX11L2 gene, located on human chromosome 2, is annotated as a DEAD/H-box helicase 11 like 2 pseudogene. Pseudogenes are generally considered non-functional copies of protein-coding genes that have accumulated mutations preventing their translation into functional proteins. Despite this annotation, some pseudogenes have been found to play active regulatory roles, for instance, by producing non-coding RNAs or acting as cis-regulatory elements [2]. Previous research has suggested the presence of an active promoter within an intronic region of DDX11L2, often discussed in the context of human chromosome evolution [3].
This study aims to independently verify the transcriptional activity of this specific intronic region of DDX11L2 by analyzing comprehensive genomic and epigenomic datasets available through the UCSC Genome Browser. We specifically investigate the presence of key epigenetic hallmarks of active promoters, the classification of cis-regulatory elements, and direct evidence of RNA Polymerase II binding.
2. Materials and Methods
2.1 Data Sources
Genomic and epigenomic data were accessed and visualized using the UCSC Genome Browser (genome.ucsc.edu), utilizing the Human Genome assembly hg38. The analysis focused on the genomic coordinates chr2:113599028-113603778, encompassing the DDX11L2 gene locus.
The following data tracks were enabled and examined in detail:
ENCODE Candidate cis-Regulatory Elements (cCREs): This track integrates data from multiple ENCODE assays to classify genomic regions based on their regulatory potential. The “full” display mode was selected to visualize the color-coded classifications (red for promoter-like, yellow for enhancer-like, blue for CTCF-bound) [4].
Layered H3K27ac: This track displays ChIP-seq signal for Histone H3 Lysine 27 acetylation, a histone modification associated with active promoters and enhancers. The “full” display mode was used to visualize peak enrichment [5].
ReMap Atlas of Regulatory Regions (RNA Polymerase II ChIP-seq): This track provides a meta-analysis of transcription factor binding sites from numerous ChIP-seq experiments. The “full” display mode was selected, and the sub-track specifically for “Pol2” (RNA Polymerase II) was enabled to visualize its binding profiles [6].
DNase I Hypersensitivity Clusters: This track indicates regions of open chromatin, which are accessible to regulatory proteins. The “full” display mode was used to observe DNase I hypersensitive sites [4].
GENCODE Genes and RefSeq Genes: These tracks were used to visualize the annotated gene structure of DDX11L2, including exons and introns.
2.2 Data Analysis
The analysis involved visual inspection of the co-localization of signals across the enabled tracks within the DDX11L2 gene region. Specific attention was paid to the first major intron, where previous studies have suggested an alternative promoter. The presence and overlap of red “Promoter-like” cCREs, H3K27ac peaks, and Pol2 binding peaks were assessed as indicators of active transcriptional initiation. The names associated with the cCREs (e.g., GSE# for GEO accession, transcription factor, and cell line) were noted to understand the experimental context of their classification.
3. Results
Analysis of the DDX11L2 gene locus on chr2 (hg38) revealed consistent evidence supporting the presence of an active alternative promoter within its first intron.
3.1 Identification of Promoter-like cis-Regulatory Elements:
The ENCODE cCREs track displayed multiple distinct red bars within the first major intron of DDX11L2, specifically localized around chr2:113,601,200 – 113,601,500. These red cCREs are computationally classified as “Promoter-like,” indicating a high likelihood of promoter activity based on integrated epigenomic data. Individual cCREs were associated with specific experimental identifiers, such as “GSE46237.TERF2.WI-38VA13,” “GSE102884.SMC3.HeLa-Kyoto_WAPL_PDS-depleted,” and “GSE102884.SMC3.HeLa-Kyoto_PDS5-depleted.” These labels indicate that the “promoter-like” classification for these regions was supported by ChIP-seq experiments targeting transcription factors like TERF2 and SMC3 in various cell lines (WI-38VA13, HeLa-Kyoto, and HeLa-Kyoto under specific depletion conditions).
3.2 Enrichment of Active Promoter Histone Marks:
A prominent peak of H3K27ac enrichment was observed in the Layered H3K27ac track. This peak directly overlapped with the cluster of red “Promoter-like” cCREs, spanning approximately chr2:113,601,200 – 113,601,700. This strong H3K27ac signal is a hallmark of active regulatory elements, including promoters.
3.3 Direct RNA Polymerase II Binding:
Crucially, the ReMap Atlas of Regulatory Regions track, specifically the sub-track for RNA Polymerase II (Pol2) ChIP-seq, exhibited a distinct peak that spatially coincided with both the H3K27ac enrichment and the “Promoter-like” cCREs in the DDX11L2 first intron. This direct binding of Pol2 is a definitive indicator of transcriptional machinery engagement at this site.
3.4 Open Chromatin State:
The presence of active histone marks and Pol2 binding strongly implies an open chromatin configuration. Examination of the DNase I Hypersensitivity Clusters track reveals a corresponding peak, further supporting the accessibility of this region for transcription factor binding and initiation.
4. Discussion
The integrated genomic data from the UCSC Genome Browser provides compelling evidence for an active alternative promoter within the first intron of the human DDX11L2 gene. The co-localization of “Promoter-like” cCREs, robust H3K27ac signals, and direct RNA Polymerase II binding collectively demonstrates that this region is actively engaged in transcriptional initiation.
The classification of cCREs as “promoter-like” (red bars) is based on a sophisticated integration of multiple ENCODE assays, reflecting a comprehensive biochemical signature of active promoters. The specific experimental identifiers associated with these cCREs (e.g., ERG, TERF2, SMC3 ChIP-seq data) highlight the diverse array of transcription factors that can bind to and contribute to the regulatory activity of a promoter. While ERG, TERF2, and SMC3 are not RNA Pol II itself, their presence at this locus, in conjunction with Pol II binding and active histone marks, indicates a complex regulatory network orchestrating transcription from this alternative promoter.
The strong H3K27ac peak serves as a critical epigenetic signature, reinforcing the active state of this promoter. H3K27ac marks regions of open chromatin that are poised for, or actively undergoing, transcription. Its direct overlap with Pol II binding further strengthens the assertion of active transcription initiation.
The direct observation of RNA Polymerase II binding is the most definitive evidence for transcriptional initiation. Pol II is the core enzyme responsible for synthesizing messenger RNA (mRNA) and many non-coding RNAs. Its presence at a specific genomic location signifies that the cellular machinery for transcription is assembled and active at that site.
The findings are particularly interesting given that DDX11L2 is annotated as a pseudogene. This study adds to the growing body of literature demonstrating that pseudogenes, traditionally considered genomic “fossils,” can acquire or retain functional regulatory roles, including acting as active promoters for non-coding RNAs or influencing the expression of neighboring genes [2]. The presence of an active alternative promoter within DDX11L2 suggests a more intricate regulatory landscape than implied by its pseudogene annotation alone.
5. Conclusion
Through the integrated analysis of ENCODE and ReMap data on the UCSC Genome Browser, this study provides strong evidence that an intronic region within the human DDX11L2 gene functions as an active alternative promoter. The co-localization of “Promoter-like” cCREs, high H3K27ac enrichment, and direct RNA Polymerase II binding collectively confirms active transcriptional initiation at this locus. These findings contribute to our understanding of the complex regulatory architecture of the human genome and highlight the functional potential of regions, such as pseudogenes, that may have been previously overlooked.
References
[1] Carninci P. and Tagami H. (2014). The FANTOM5 project and its implications for mammalian biology. F1000Prime Reports, 6: 104.
[2] Poliseno L. (2015). Pseudogenes: Architects of complexity in gene regulation. Current Opinion in Genetics & Development, 31: 79-84.
[3] Tomkins J.P. (2013). Alleged Human Chromosome 2 “Fusion Site” Encodes an Active DNA Binding Domain Inside a Complex and Highly Expressed Gene—Negating Fusion. Answers Research Journal, 6: 367–375. (Note: While this paper was a starting point, the current analysis uses independent data for verification).
[4] ENCODE Project Consortium. (2012). An integrated encyclopedia of DNA elements in the human genome. Nature, 489(7414): 57–74.
[5] Rada-Iglesias A., et al. (2011). A unique chromatin signature identifies active enhancers and genes in human embryonic stem cells. Nature Cell Biology, 13(9): 1003–1013.
[6] Chèneby J., et al. (2018). ReMap 2018: an updated atlas of regulatory regions from an integrative analysis of DNA-binding ChIP-seq experiments. Nucleic Acids Research, 46(D1): D267–D275.
From my perspective, society isn’t some grand, top-down invention or a purely artificial construct. Instead, it’s a natural outgrowth of human interaction, an organic creation. This organic origin gives society a fascinating, dualistic nature: it’s both a source of conflict and a fertile ground for cooperation, a necessary evil, and a crucial tool for individual flourishing. I see these seemingly opposing ideas not as separate or contradictory, but as deeply intertwined.
The inherent conflict within society comes from the undeniable reality of human imperfection. As fallen creatures, individuals will always have competing interests, differing desires, and a natural lean toward self-interest and corruption. This doesn’t mean we’re in a constant state of overt warfare, but rather a perpetual tension over resources, values, and the direction we take as a collective. Yet, our natural inclination to interact also fosters cooperation. Things like specialization, security, the pursuit of knowledge, and companionship make a collective invaluable. Society, then, emerges from this very tension—the delicate balance between individual will and collective order.
Our Place as Individuals in the Social Fabric
An individual’s relationship to society is equally nuanced. In my view, the paramount command for each of us is to love our neighbor and orient our lives toward God. This core Christian ethical responsibility dictates an outward-looking concern for others, yet it critically anchors responsibility within our own sphere of influence. While the collective good is undeniably important and should be prioritized when we can genuinely affect change, our ultimate responsibility isn’t to the totality of society—what Dostoevsky called ‘general love of humanity’—but for what we can directly control: the self.
This means cultivating personal virtue, making ethical choices in daily interactions, and contributing positively within our own communities. Society, in turn, has a duty to its members, but this duty is reciprocal. It flows from the recognition that individuals have responsibilities toward each other. It’s not a top-down benevolence, but a framework of mutual obligation.
Understanding Freedom and Authority
Freedom, in this context, isn’t absolute license. All freedom is either freedom from or freedom to. We should possess freedom from things that cause harm—whether it’s physical violence, coercive manipulation, or the unjust suppression of conscience. Equally, we should have the freedom to choose things that benefit us, to pursue our vocations, and to act on good impulses. Crucially, to exercise these freedoms, we must also be free to express our perceptions about what’s beneficial and harmful, and to act on the former while restricting the latter.
Broader, or higher, societal authority should be clearly codified into law, discriminating against no one group. These laws should ideally be general rules of conduct, equally applicable to all, providing a predictable framework for individual action rather than dictating specific outcomes.
This idea comes from a fundamental principle of governance, which I derive from thinkers like Hayek and Mill: broader authority—the state or collective institutions—should err on the side of fewer restrictions and regulations. Its role is to establish and enforce the rules of the game, not to direct the play itself. Conversely, narrower authority, extending to its most narrow point in the self, should err on the side of being too restricted. This means exercising personal moral discipline and self-governance.
This plays out with a clear distinction: the king declares that murder is forbidden, establishing a universal legal boundary, while the individual forbids hate in his own heart, engaging in the continuous, internal struggle for virtue. The former creates external order; the latter cultivates internal righteousness. The moment this moral hierarchy is dismembered is likely the same moment society begins to decline.
The Unending Struggle
Human beings are fallen creatures, and none of this will ever play out as a utopian vision. We’re not so malleable, in a Marxist sense, that our nature can be entirely shaped by policy or environmental conditions; there are inherent tendencies and proclivities that resist perfect social engineering. Nor are humans so inherently good that they don’t tend toward corruption when power is consolidated or accountability is removed. While humans are capable of immense wonders, they are equally capable of great atrocities. It’s not wrong to call humanity bad in its fallen state, but to call us irredeemable would be antithetical to the Christian ethos that informs my worldview.
The telos of man, our ultimate purpose, is to obey God’s commands. Ideally, institutions should facilitate that process, creating an environment conducive to moral flourishing. However, due to human imperfection and the inherent limitations of collective structures, institutions are, perhaps, not capable of reaching that ideal state in their earthly manifestation.
In many ways, I identify strongly with Friedrich Hayek’s arguments in The Road to Serfdom. His critique of collectivist policies and central planning resonates with my understanding of human nature and the necessary boundaries of societal authority. Hayek meticulously demonstrates how attempts to centrally plan society toward specific, desirable ends, even with the best intentions, inevitably lead to a loss of individual liberty and an escalation of coercive power and totalitarianism. I maintain a tentative rule-of-law position while I wait for the Lawmaker.
Further Reading:
Dostoevsky, Fyodor.The Brothers Karamazov
Hayek, F. A.The Road to Serfdom
Marx, Karl, and Engels, Friedrich.The Communist Manifesto